5 Nearest neighbours
5.1 Introduction
k-NN is by far the simplest method of supervised learning we will cover in this course. It is a non-parametric method that can be used for both classification (predicting class membership) and regression (estimating continuous variables). k-NN is categorized as instance based (memory based) learning, because all computation is deferred until classification. The most computationally demanding aspects of k-NN are finding neighbours and storing the entire learning set.
A simple k-NN classification rule (figure 5.1) would proceed as follows:
- when presented with a new observation, find the k closest samples in the learning set
- predict the class by majority vote

Figure 5.1: Illustration of k-nn classification. In this example we have two classes: blue squares and red triangles. The green circle represents a test object. If k=3 (solid line circle) the test object is assigned to the red triangle class. If k=5 the test object is assigned to the blue square class. By Antti Ajanki AnAj - Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=2170282
A basic implementation of k-NN regression would calculate the average of the numerical outcome of the k nearest neighbours.
The number of neighbours k can have a considerable impact on the predictive performance of k-NN in both classification and regression. The optimal value of k should be chosen using cross-validation.
Euclidean distance is the most widely used distance metric in k-nn, and will be used in the examples and exercises in this chapter. However, other distance metrics can be used.
Euclidean distance: \[\begin{equation} distance\left(p,q\right)=\sqrt{\sum_{i=1}^{n} (p_i-q_i)^2} \tag{5.1} \end{equation}\]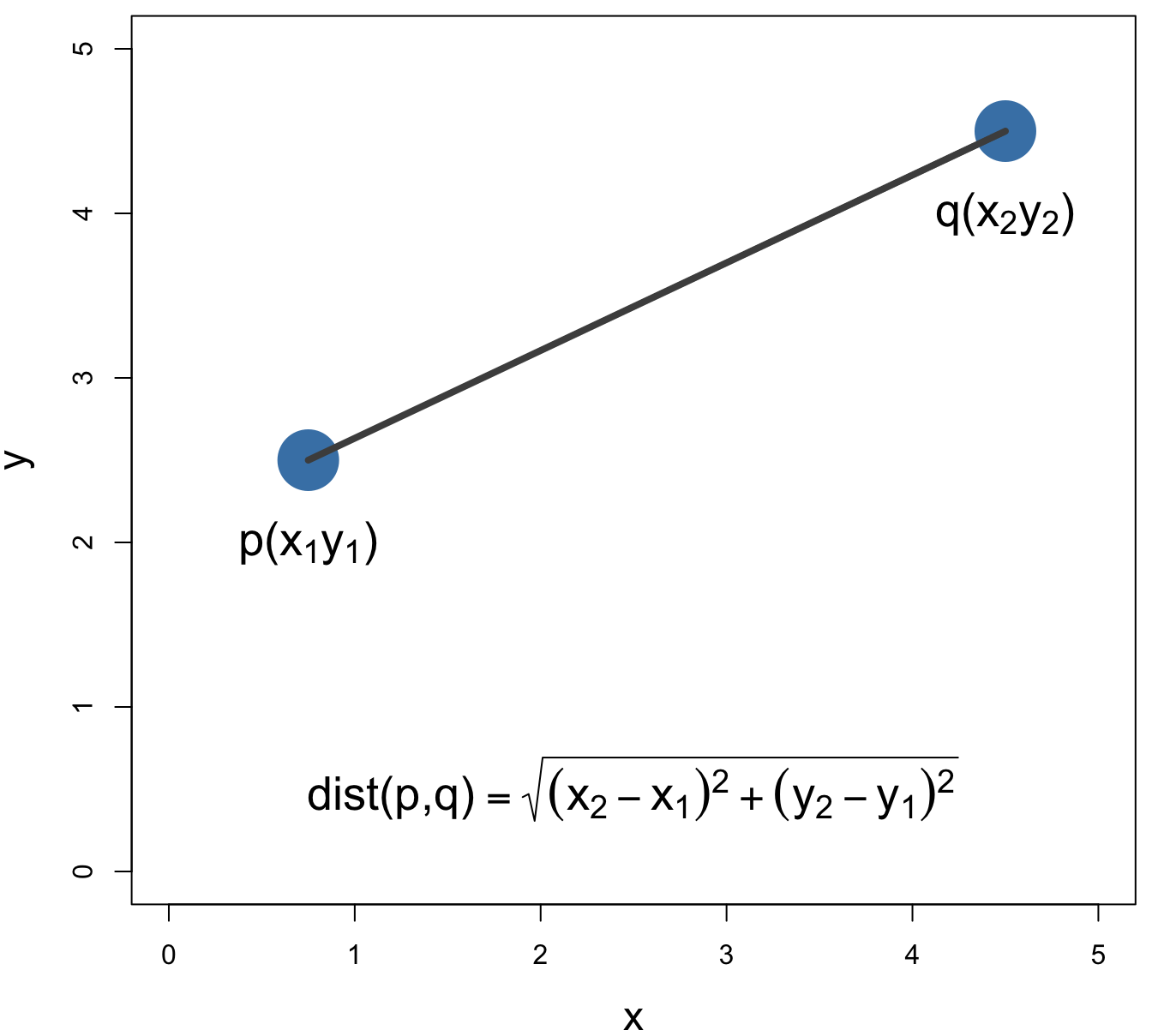
Figure 5.2: Euclidean distance.
5.2 Classification: simulated data
A simulated data set will be used to demonstrate:
- bias-variance trade-off
- the knn function in R
- plotting decision boundaries
- choosing the optimum value of k
The dataset has been partitioned into training and test sets.
Load data
load("data/example_binary_classification/bin_class_example.rda")
str(xtrain)## 'data.frame': 400 obs. of 2 variables:
## $ V1: num -0.223 0.944 2.36 1.846 1.732 ...
## $ V2: num -1.153 -0.827 -0.128 2.014 -0.574 ...str(xtest)## 'data.frame': 400 obs. of 2 variables:
## $ V1: num 2.09 2.3 2.07 1.65 1.18 ...
## $ V2: num -1.009 1.0947 0.1644 0.3243 -0.0277 ...summary(as.factor(ytrain))## 0 1
## 200 200summary(as.factor(ytest))## 0 1
## 200 200library(ggplot2)
library(GGally)
library(RColorBrewer)
point_shapes <- c(15,17)
point_colours <- brewer.pal(3,"Dark2")
point_size = 2
ggplot(xtrain, aes(V1,V2)) +
geom_point(col=point_colours[ytrain+1], shape=point_shapes[ytrain+1],
size=point_size) +
ggtitle("train") +
theme_bw() +
theme(plot.title = element_text(size=25, face="bold"), axis.text=element_text(size=15),
axis.title=element_text(size=20,face="bold"))
ggplot(xtest, aes(V1,V2)) +
geom_point(col=point_colours[ytest+1], shape=point_shapes[ytest+1],
size=point_size) +
ggtitle("test") +
theme_bw() +
theme(plot.title = element_text(size=25, face="bold"), axis.text=element_text(size=15),
axis.title=element_text(size=20,face="bold"))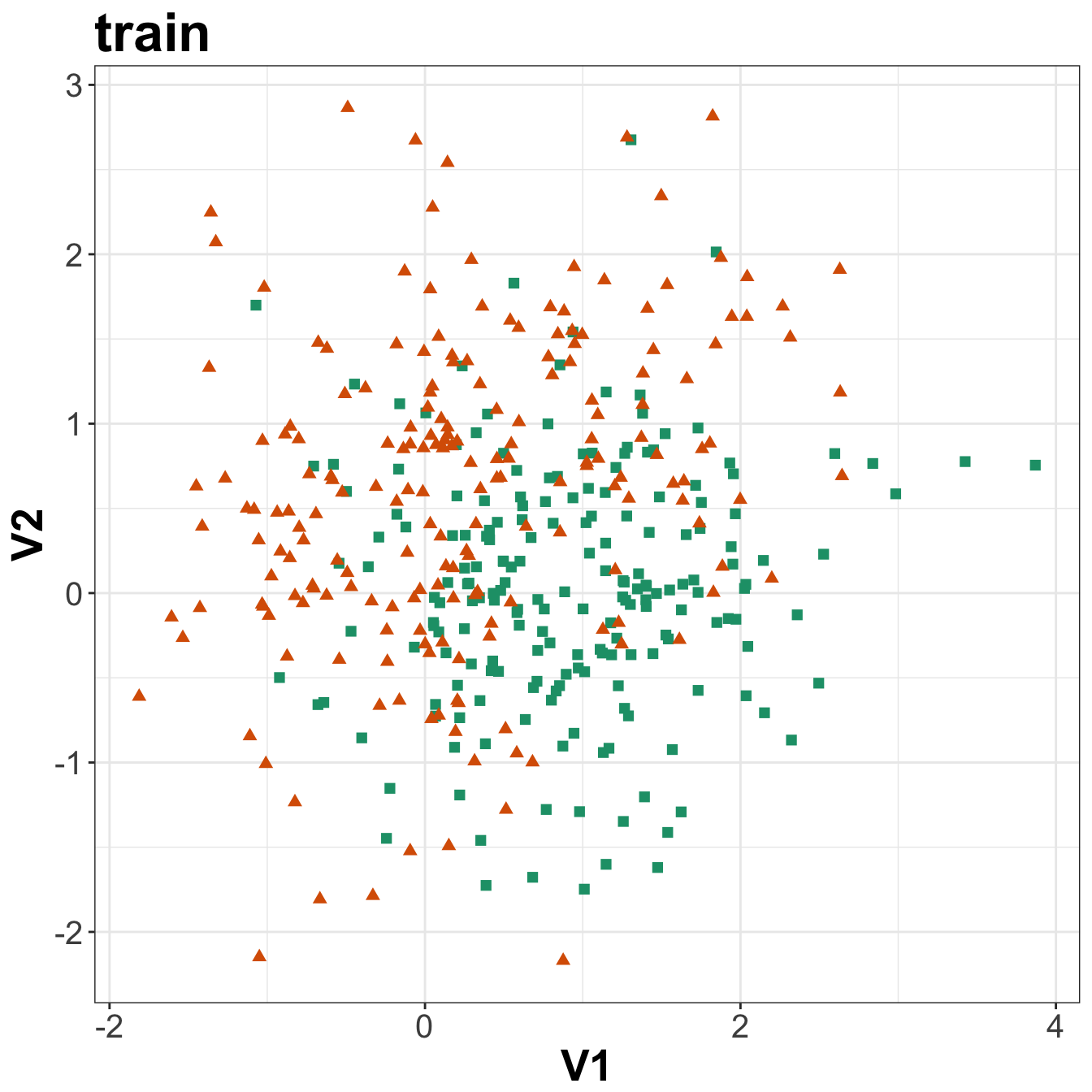
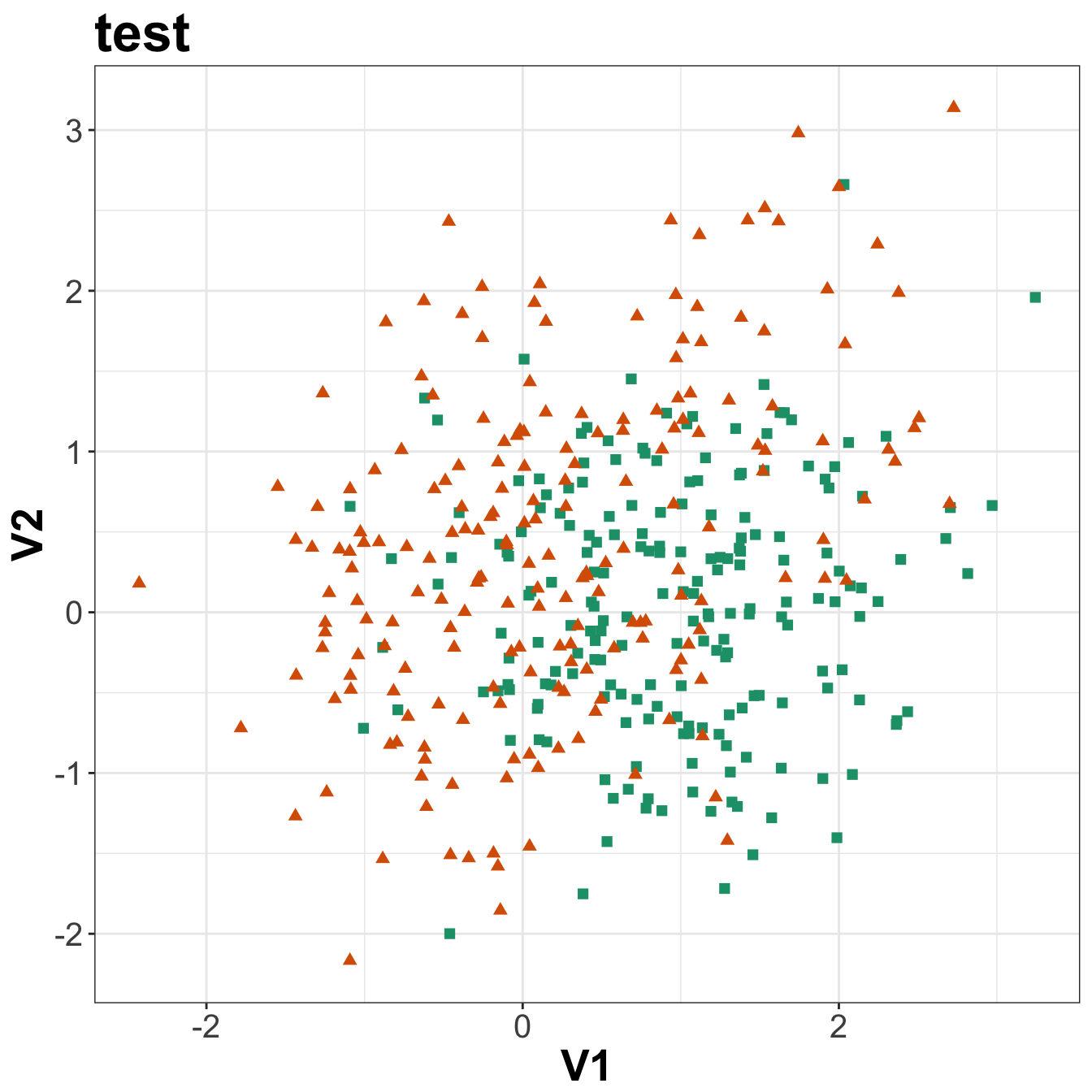
Figure 5.3: Scatterplots of the simulated training and test data sets that will be used in the demonstration of binary classification using k-nn
5.2.1 knn function
For k-nn classification and regression we will use the knn function in the package class.
library(class)Arguments to knn
train: matrix or data frame of training set cases.test: matrix or data frame of test set cases. A vector will be interpreted as a row vector for a single case.cl: factor of true classifications of training setk: number of neighbours considered.l: minimum vote for definite decision, otherwise doubt. (More precisely, less than k-l dissenting votes are allowed, even if k is increased by ties.)prob: If this is true, the proportion of the votes for the winning class are returned as attribute prob.use.all: controls handling of ties. If true, all distances equal to the kth largest are included. If false, a random selection of distances equal to the kth is chosen to use exactly k neighbours.
Let us perform k-nn on the training set with k=1. We will use the confusionMatrix function from the caret package to summarize performance of the classifier.
library(caret)## Loading required package: latticeknn1train <- class::knn(train=xtrain, test=xtrain, cl=ytrain, k=1)
confusionMatrix(knn1train, ytrain)## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 200 0
## 1 0 200
##
## Accuracy : 1
## 95% CI : (0.9908, 1)
## No Information Rate : 0.5
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 1
## Mcnemar's Test P-Value : NA
##
## Sensitivity : 1.0
## Specificity : 1.0
## Pos Pred Value : 1.0
## Neg Pred Value : 1.0
## Prevalence : 0.5
## Detection Rate : 0.5
## Detection Prevalence : 0.5
## Balanced Accuracy : 1.0
##
## 'Positive' Class : 0
## The classifier performs perfectly on the training set, because with k=1, each observation is being predicted by itself!
Now let use the training set to predict on the test set.
knn1test <- class::knn(train=xtrain, test=xtest, cl=ytrain, k=1)
confusionMatrix(knn1test, ytest)## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 131 81
## 1 69 119
##
## Accuracy : 0.625
## 95% CI : (0.5755, 0.6726)
## No Information Rate : 0.5
## P-Value [Acc > NIR] : 3.266e-07
##
## Kappa : 0.25
## Mcnemar's Test P-Value : 0.3691
##
## Sensitivity : 0.6550
## Specificity : 0.5950
## Pos Pred Value : 0.6179
## Neg Pred Value : 0.6330
## Prevalence : 0.5000
## Detection Rate : 0.3275
## Detection Prevalence : 0.5300
## Balanced Accuracy : 0.6250
##
## 'Positive' Class : 0
## Performance on the test set is not so good. This is an example of a classifier being over-fitted to the training set.
5.2.2 Plotting decision boundaries
Since we have just two dimensions we can visualize the decision boundary generated by the k-nn classifier in a 2D scatterplot. Situations where your original data set contains only two variables will be rare, but it is not unusual to reduce a high-dimensional data set to just two dimensions using the methods that will be discussed in chapter 9. Therefore, knowing how to plot decision boundaries will potentially be helpful for many different datasets and classifiers.
Create a grid so we can predict across the full range of our variables V1 and V2.
gridSize <- 150
v1limits <- c(min(c(xtrain[,1],xtest[,1])),max(c(xtrain[,1],xtest[,1])))
tmpV1 <- seq(v1limits[1],v1limits[2],len=gridSize)
v2limits <- c(min(c(xtrain[,2],xtest[,2])),max(c(xtrain[,2],xtest[,2])))
tmpV2 <- seq(v2limits[1],v2limits[2],len=gridSize)
xgrid <- expand.grid(tmpV1,tmpV2)
names(xgrid) <- names(xtrain)Predict values of all elements of grid.
knn1grid <- class::knn(train=xtrain, test=xgrid, cl=ytrain, k=1)
V3 <- as.numeric(as.vector(knn1grid))
xgrid <- cbind(xgrid, V3)Plot
point_shapes <- c(15,17)
point_colours <- brewer.pal(3,"Dark2")
point_size = 2
ggplot(xgrid, aes(V1,V2)) +
geom_point(col=point_colours[knn1grid], shape=16, size=0.3) +
geom_point(data=xtrain, aes(V1,V2), col=point_colours[ytrain+1],
shape=point_shapes[ytrain+1], size=point_size) +
geom_contour(data=xgrid, aes(x=V1, y=V2, z=V3), breaks=0.5, col="grey30") +
ggtitle("train") +
theme_bw() +
theme(plot.title = element_text(size=25, face="bold"), axis.text=element_text(size=15),
axis.title=element_text(size=20,face="bold"))
ggplot(xgrid, aes(V1,V2)) +
geom_point(col=point_colours[knn1grid], shape=16, size=0.3) +
geom_point(data=xtest, aes(V1,V2), col=point_colours[ytest+1],
shape=point_shapes[ytrain+1], size=point_size) +
geom_contour(data=xgrid, aes(x=V1, y=V2, z=V3), breaks=0.5, col="grey30") +
ggtitle("test") +
theme_bw() +
theme(plot.title = element_text(size=25, face="bold"), axis.text=element_text(size=15),
axis.title=element_text(size=20,face="bold"))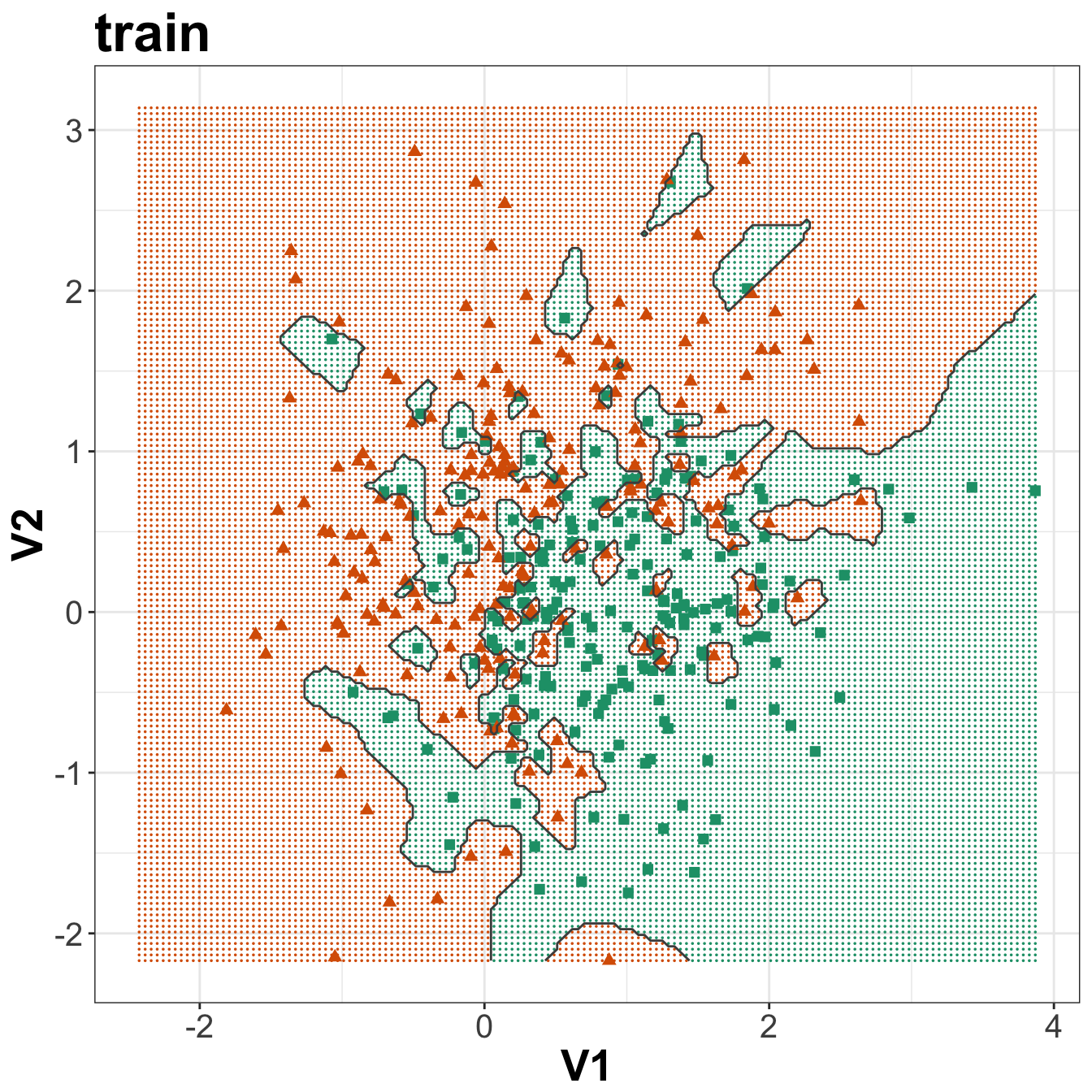
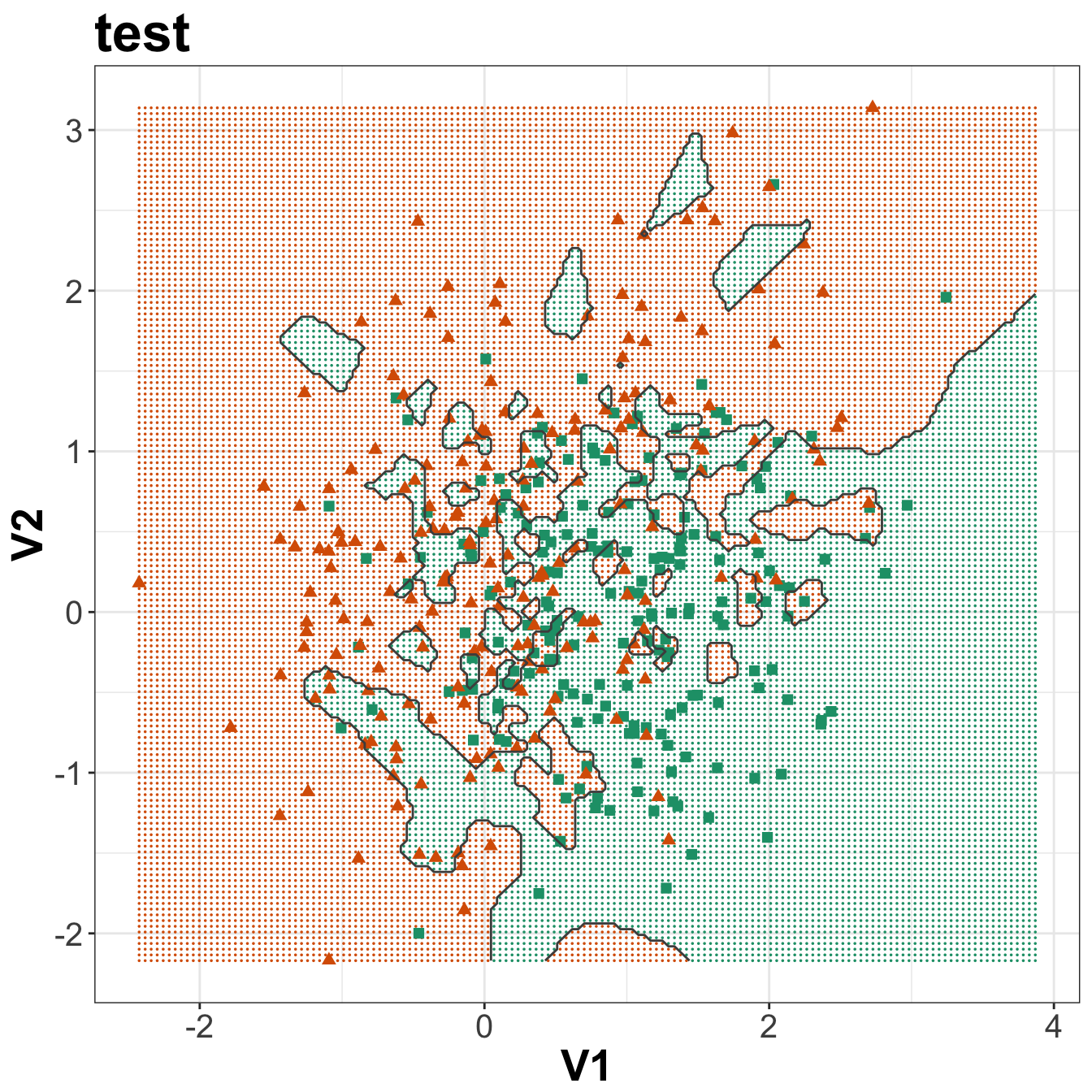
Figure 5.4: Binary classification of the simulated training and test sets with k=1.
5.2.3 Bias-variance tradeoff
The bias–variance tradeoff is the problem of simultaneously minimizing two sources of error that prevent supervised learning algorithms from generalizing beyond their training set:
- The bias is error from erroneous assumptions in the learning algorithm. High bias can cause an algorithm to miss the relevant relations between features and target outputs (underfitting).
- The variance is error from sensitivity to small fluctuations in the training set. High variance can cause an algorithm to model the random noise in the training data, rather than the intended outputs (overfitting).
To demonstrate this phenomenon, let us look at the performance of the k-nn classifier over a range of values of k. First we will define a function to create a sequence of log spaced values. This is the lseq function from the emdbook package:
lseq <- function(from, to, length.out) {
exp(seq(log(from), log(to), length.out = length.out))
}Get log spaced sequence of length 20, round and then remove any duplicates resulting from rounding.
s <- unique(round(lseq(1,400,20)))
length(s)## [1] 19train_error <- sapply(s, function(i){
yhat <- knn(xtrain, xtrain, ytrain, i)
return(1-mean(as.numeric(as.vector(yhat))==ytrain))
})
test_error <- sapply(s, function(i){
yhat <- knn(xtrain, xtest, ytrain, i)
return(1-mean(as.numeric(as.vector(yhat))==ytest))
})
k <- rep(s, 2)
set <- c(rep("train", length(s)), rep("test", length(s)))
error <- c(train_error, test_error)
misclass_errors <- data.frame(k, set, error)ggplot(misclass_errors, aes(x=k, y=error, group=set)) +
geom_line(aes(colour=set, linetype=set), size=1.5) +
scale_x_log10() +
ylab("Misclassification Errors") +
theme_bw() +
theme(legend.position = c(0.5, 0.25), legend.title=element_blank(),
legend.text=element_text(size=12),
axis.title.x=element_text(face="italic", size=12))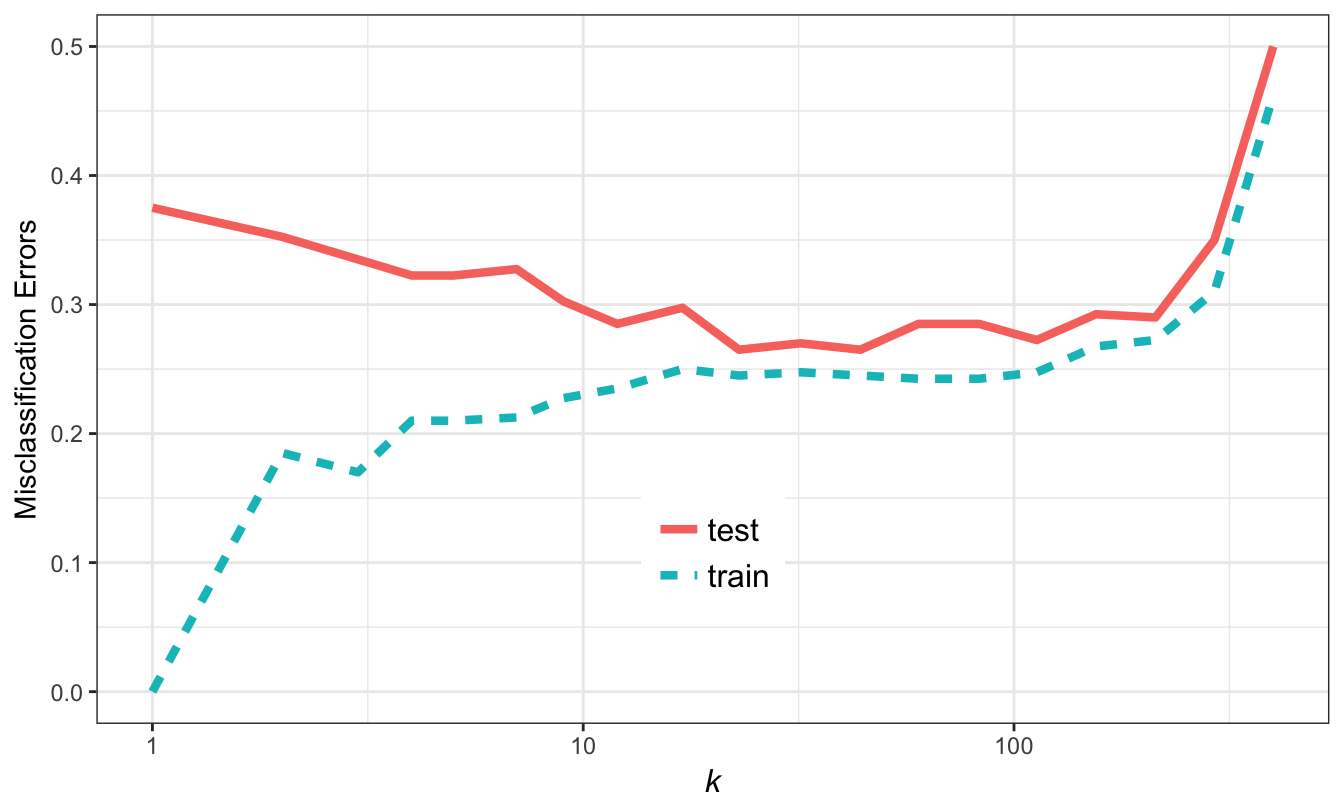
Figure 5.5: Misclassification errors as a function of neighbourhood size.
We see excessive variance (overfitting) at low values of k, and bias (underfitting) at high values of k.
5.2.4 Choosing k
We will use the caret library. Caret provides a unified interface to a huge range of supervised learning packages in R. The design of its tools encourages best practice, especially in relation to cross-validation and testing. Additionally, it has automatic parallel processing built in, which is a significant advantage when dealing with large data sets.
library(caret)To take advantage of Caret’s parallel processing functionality, we simply need to load the doMC package and register workers:
library(doMC)## Loading required package: foreach## Loading required package: iterators## Loading required package: parallelregisterDoMC()To find out how many cores we have registered we can use:
getDoParWorkers()## [1] 2The caret function train is used to fit predictive models over different values of k. The function trainControl is used to specify a list of computational and resampling options, which will be passed to train. We will start by configuring our cross-validation procedure using trainControl.
We would like to make this demonstration reproducible and because we will be running the models in parallel, using the set.seed function alone is not sufficient. In addition to using set.seed we have to make use of the optional seeds argument to trainControl. We need to supply seeds with a list of integers that will be used to set the seed at each sampling iteration. The list is required to have a length of B+1, where B is the number of resamples. We will be repeating 10-fold cross-validation a total of ten times and so our list must have a length of 101. The first B elements of the list are required to be vectors of integers of length M, where M is the number of models being evaluated (in this case 19). The last element of the list only needs to be a single integer, which will be used for the final model.
First we generate our list of seeds.
set.seed(42)
seeds <- vector(mode = "list", length = 101)
for(i in 1:100) seeds[[i]] <- sample.int(1000, 19)
seeds[[101]] <- sample.int(1000,1)We can now use trainControl to create a list of computational options for resampling.
tc <- trainControl(method="repeatedcv",
number = 10,
repeats = 10,
seeds = seeds)There are two options for choosing the values of k to be evaluated by the train function:
- Pass a data.frame of values of k to the tuneGrid argument of train.
- Specify the number of different levels of k using the tuneLength function and allow train to pick the actual values.
We will use the first option, so that we can try the values of k we examined earlier. The vector of values of k we created earlier should be converted into a data.frame.
s <- data.frame(s)
names(s) <- "k"We are now ready to run the cross-validation.
knnFit <- train(xtrain, as.factor(ytrain),
method="knn",
tuneGrid=s,
trControl=tc)
knnFit## k-Nearest Neighbors
##
## 400 samples
## 2 predictor
## 2 classes: '0', '1'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 10 times)
## Summary of sample sizes: 360, 360, 360, 360, 360, 360, ...
## Resampling results across tuning parameters:
##
## k Accuracy Kappa
## 1 0.63300 0.2660
## 2 0.63875 0.2775
## 3 0.67375 0.3475
## 4 0.67900 0.3580
## 5 0.69575 0.3915
## 7 0.71100 0.4220
## 9 0.71775 0.4355
## 12 0.71500 0.4300
## 17 0.72675 0.4535
## 23 0.73800 0.4760
## 32 0.73725 0.4745
## 44 0.73875 0.4775
## 60 0.74850 0.4970
## 83 0.75500 0.5100
## 113 0.73500 0.4700
## 155 0.72575 0.4515
## 213 0.70750 0.4150
## 292 0.68825 0.3765
## 400 0.51300 0.0260
##
## Accuracy was used to select the optimal model using the largest value.
## The final value used for the model was k = 83.where O is the observed accuracy and E is the expected accuracy based on the marginal totals of the confusion matrix. Cohen’s Kappa takes values between -1 and 1; a value of zero indicates no agreement between the observed and predicted classes, while a value of one shows perfect concordance of the model prediction and the observed classes. If the prediction is in the opposite direction of the truth, a negative value will be obtained, but large negative values are rare in practice (Kuhn and Johnson 2013).
We can plot accuracy (determined from repeated cross-validation) as a function of neighbourhood size.
plot(knnFit)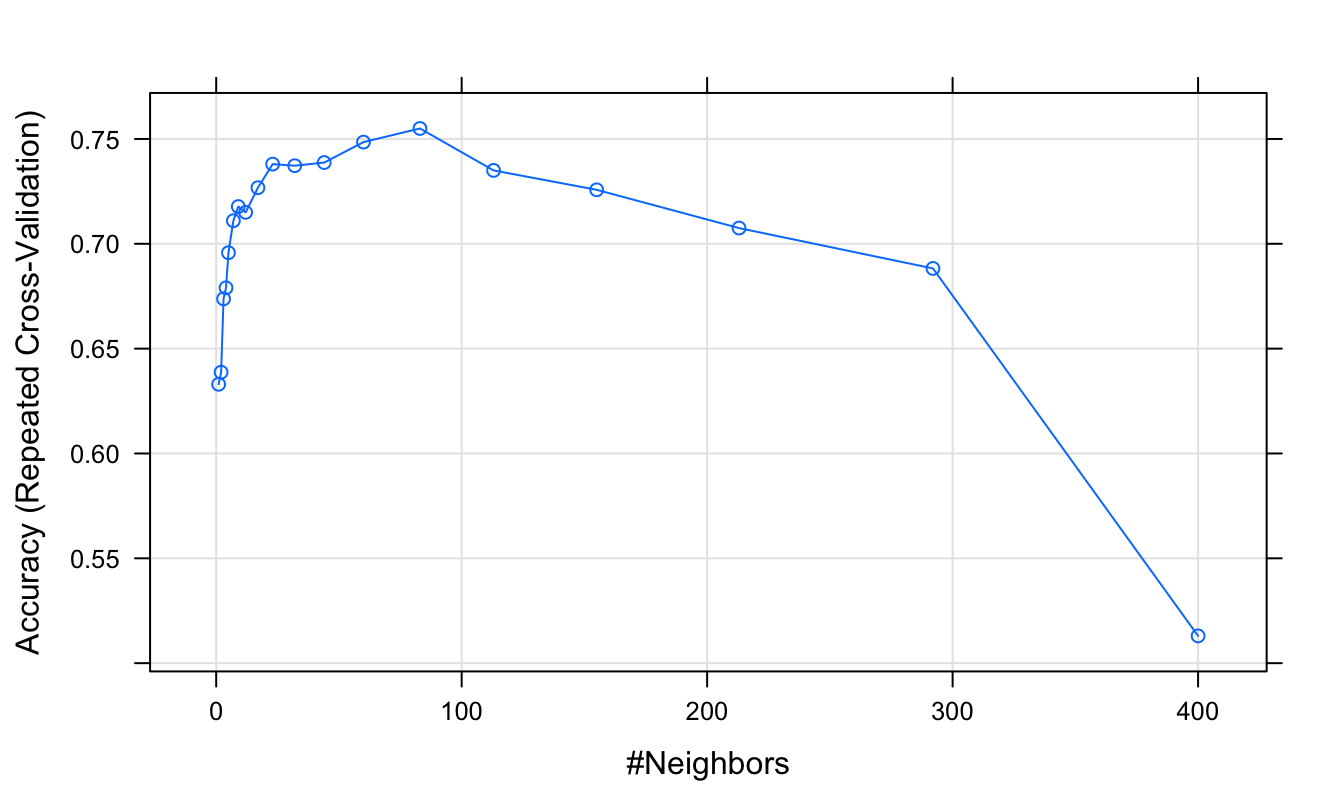
Figure 5.6: Accuracy (repeated cross-validation) as a function of neighbourhood size.
We can also plot other performance metrics, such as Cohen’s Kappa, using the metric argument.
plot(knnFit, metric="Kappa")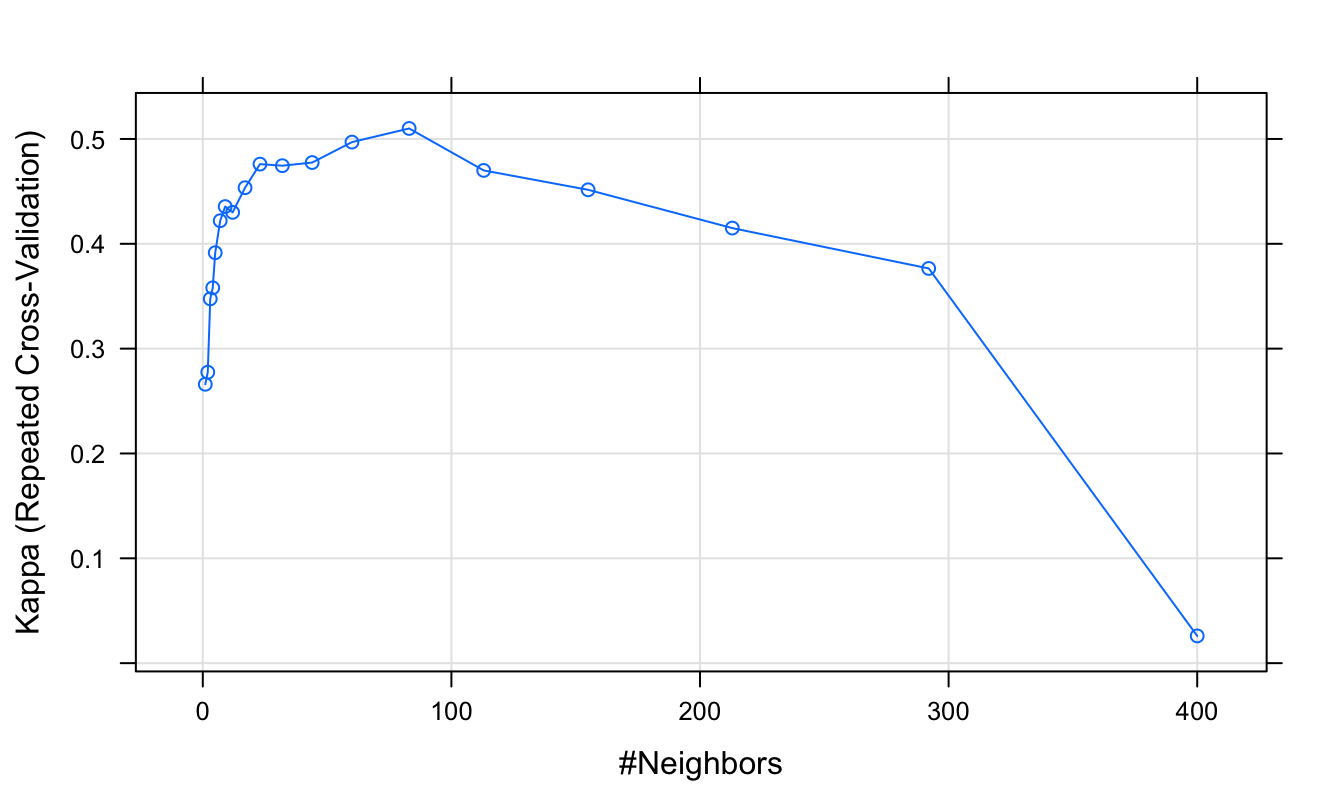
Figure 5.7: Cohen’s Kappa (repeated cross-validation) as a function of neighbourhood size.
Let us now evaluate how our classifier performs on the test set.
test_pred <- predict(knnFit, xtest)
confusionMatrix(test_pred, ytest)## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 154 68
## 1 46 132
##
## Accuracy : 0.715
## 95% CI : (0.668, 0.7588)
## No Information Rate : 0.5
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.43
## Mcnemar's Test P-Value : 0.0492
##
## Sensitivity : 0.7700
## Specificity : 0.6600
## Pos Pred Value : 0.6937
## Neg Pred Value : 0.7416
## Prevalence : 0.5000
## Detection Rate : 0.3850
## Detection Prevalence : 0.5550
## Balanced Accuracy : 0.7150
##
## 'Positive' Class : 0
## Scatterplots with decision boundaries can be plotted using the methods described earlier. First create a grid so we can predict across the full range of our variables V1 and V2:
gridSize <- 150
v1limits <- c(min(c(xtrain[,1],xtest[,1])),max(c(xtrain[,1],xtest[,1])))
tmpV1 <- seq(v1limits[1],v1limits[2],len=gridSize)
v2limits <- c(min(c(xtrain[,2],xtest[,2])),max(c(xtrain[,2],xtest[,2])))
tmpV2 <- seq(v2limits[1],v2limits[2],len=gridSize)
xgrid <- expand.grid(tmpV1,tmpV2)
names(xgrid) <- names(xtrain)Predict values of all elements of grid.
knn1grid <- predict(knnFit, xgrid)
V3 <- as.numeric(as.vector(knn1grid))
xgrid <- cbind(xgrid, V3)Plot
point_shapes <- c(15,17)
point_colours <- brewer.pal(3,"Dark2")
point_size = 2
ggplot(xgrid, aes(V1,V2)) +
geom_point(col=point_colours[knn1grid], shape=16, size=0.3) +
geom_point(data=xtrain, aes(V1,V2), col=point_colours[ytrain+1],
shape=point_shapes[ytrain+1], size=point_size) +
geom_contour(data=xgrid, aes(x=V1, y=V2, z=V3), breaks=0.5, col="grey30") +
ggtitle("train") +
theme_bw() +
theme(plot.title = element_text(size=25, face="bold"), axis.text=element_text(size=15),
axis.title=element_text(size=20,face="bold"))
ggplot(xgrid, aes(V1,V2)) +
geom_point(col=point_colours[knn1grid], shape=16, size=0.3) +
geom_point(data=xtest, aes(V1,V2), col=point_colours[ytest+1],
shape=point_shapes[ytrain+1], size=point_size) +
geom_contour(data=xgrid, aes(x=V1, y=V2, z=V3), breaks=0.5, col="grey30") +
ggtitle("test") +
theme_bw() +
theme(plot.title = element_text(size=25, face="bold"), axis.text=element_text(size=15),
axis.title=element_text(size=20,face="bold"))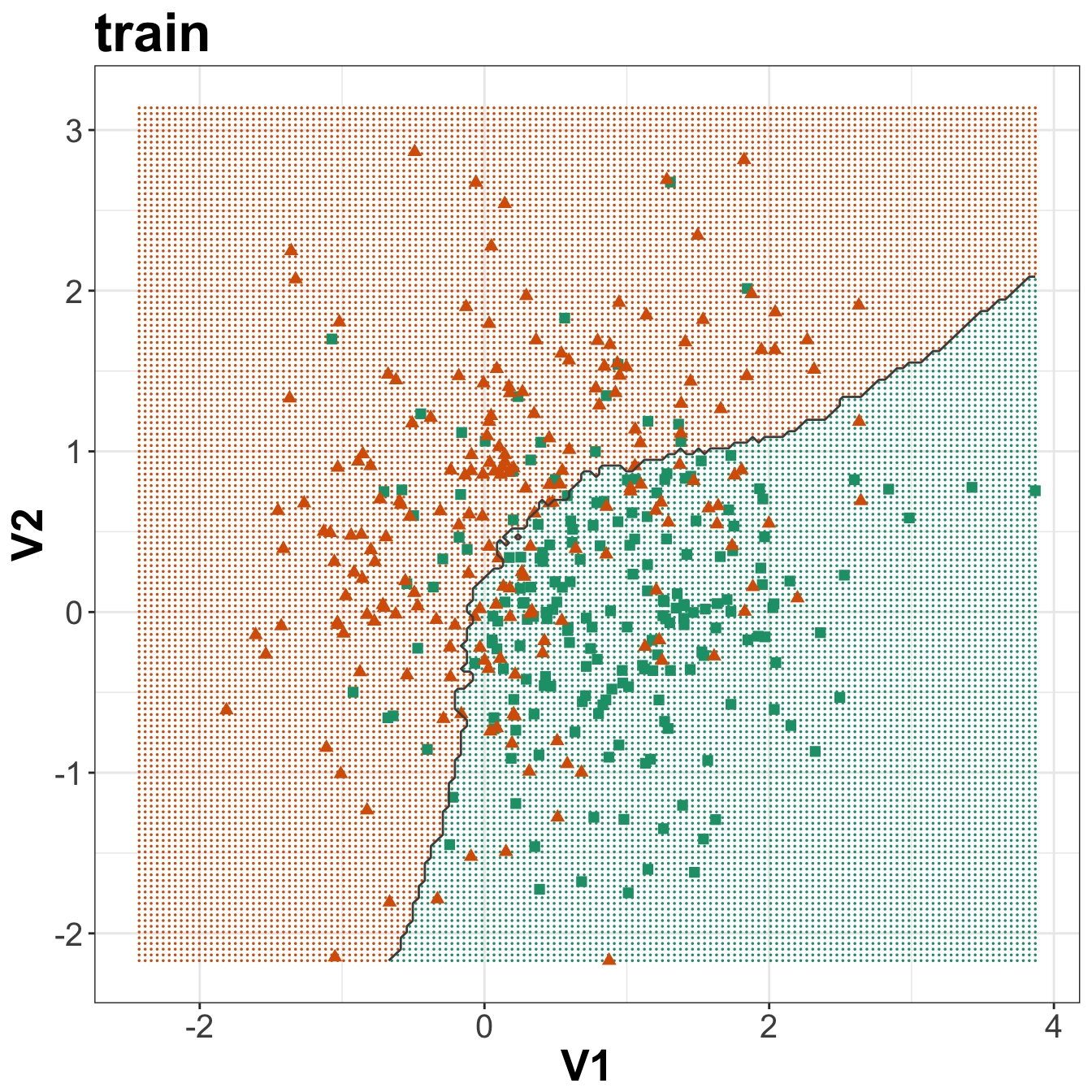
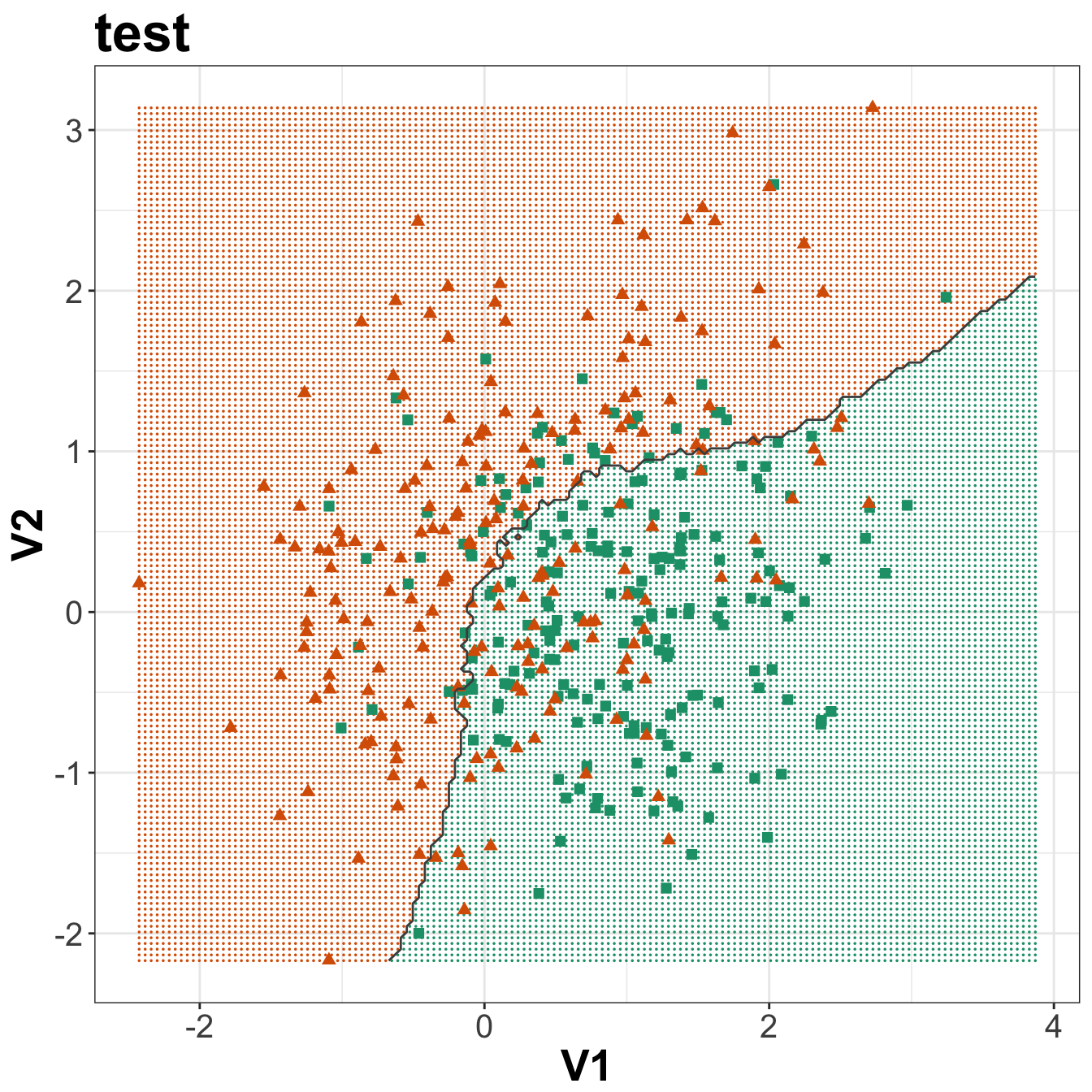
Figure 5.8: Binary classification of the simulated training and test sets with k=83.
5.3 Classification: cell segmentation
The simulated data in our previous example were randomly sampled from a normal (Gaussian) distribution and so did not require pre-processing. In practice, data collected in real studies often require transformation and/or filtering. Furthermore, the simulated data contained only two predictors; in practice, you are likely to have many variables. For example, in a gene expression study you might have thousands of variables. When using k-nn for classification or regression, removing variables that are not associated with the outcome of interest may improve the predictive power of the model. The process of choosing the best predictors from the available variables is known as feature selection. For honest estimates of model performance, pre-processing and feature selection should be performed within the loops of the cross validation process.
5.3.1 Cell segmentation data set
Pre-processing and feature selection will be demonstrated using the cell segmentation data of (A. A. Hill et al. (2007)). High Content Screening (HCS) automates the collection and analysis of biological images of cultured cells. However, image segmentation algorithms are not perfect and sometimes do not reliably quantitate the morphology of cells. Hill et al. sought to differentiate between well- and poorly-segmented cells based on the morphometric data collected in HCS. If poorly-segmented cells can be automatically detected and eliminated, then the accuracy of studies using HCS will be improved. Hill et al. collected morphometric data on 2019 cells and asked human reviewers to classify the cells as well- or poorly-segmented.
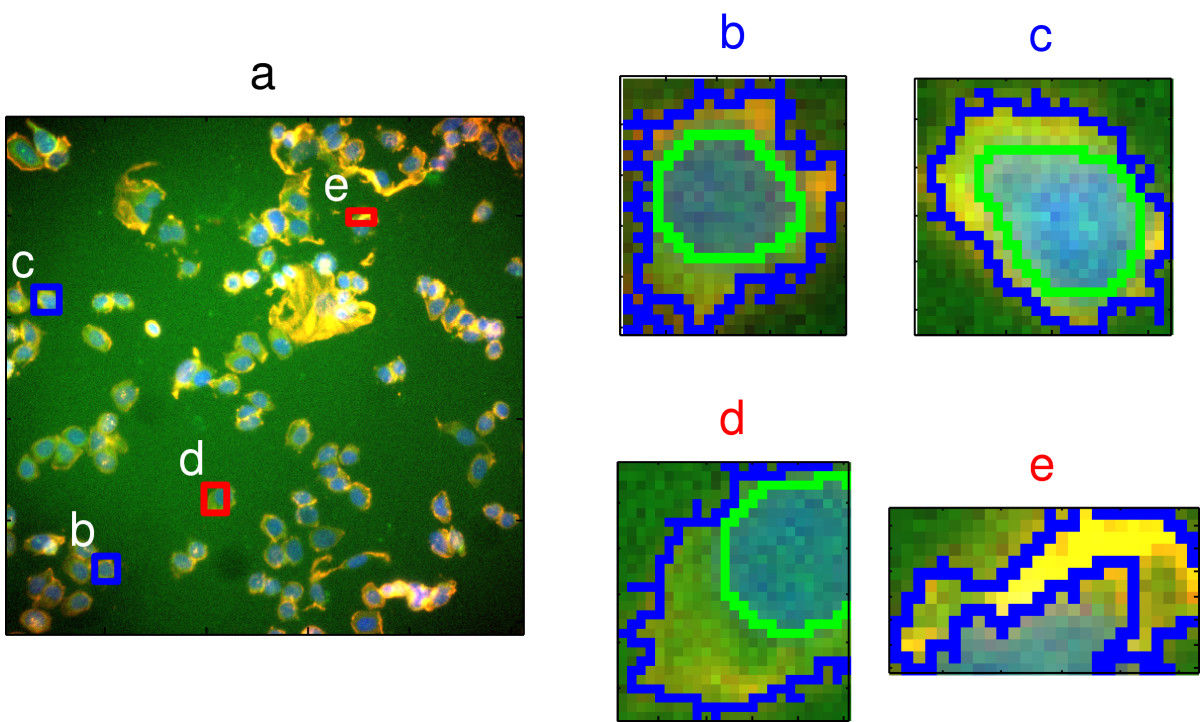
Figure 5.9: Image segmentation in high content screening. Images b and c are examples of well-segmented cells; d and e show poor-segmentation. Source: Hill(2007) https://doi.org/10.1186/1471-2105-8-340
This data set is one of several included in caret.
data(segmentationData)
str(segmentationData)## 'data.frame': 2019 obs. of 61 variables:
## $ Cell : int 207827637 207932307 207932463 207932470 207932455 207827656 207827659 207827661 207932479 207932480 ...
## $ Case : Factor w/ 2 levels "Test","Train": 1 2 2 2 1 1 1 1 1 1 ...
## $ Class : Factor w/ 2 levels "PS","WS": 1 1 2 1 1 2 2 1 2 2 ...
## $ AngleCh1 : num 143.25 133.75 106.65 69.15 2.89 ...
## $ AreaCh1 : int 185 819 431 298 285 172 177 251 495 384 ...
## $ AvgIntenCh1 : num 15.7 31.9 28 19.5 24.3 ...
## $ AvgIntenCh2 : num 4.95 206.88 116.32 102.29 112.42 ...
## $ AvgIntenCh3 : num 9.55 69.92 63.94 28.22 20.47 ...
## $ AvgIntenCh4 : num 2.21 164.15 106.7 31.03 40.58 ...
## $ ConvexHullAreaRatioCh1 : num 1.12 1.26 1.05 1.2 1.11 ...
## $ ConvexHullPerimRatioCh1: num 0.92 0.797 0.935 0.866 0.957 ...
## $ DiffIntenDensityCh1 : num 29.5 31.9 32.5 26.7 31.6 ...
## $ DiffIntenDensityCh3 : num 13.8 43.1 36 22.9 21.7 ...
## $ DiffIntenDensityCh4 : num 6.83 79.31 51.36 26.39 25.03 ...
## $ EntropyIntenCh1 : num 4.97 6.09 5.88 5.42 5.66 ...
## $ EntropyIntenCh3 : num 4.37 6.64 6.68 5.44 5.29 ...
## $ EntropyIntenCh4 : num 2.72 7.88 7.14 5.78 5.24 ...
## $ EqCircDiamCh1 : num 15.4 32.3 23.4 19.5 19.1 ...
## $ EqEllipseLWRCh1 : num 3.06 1.56 1.38 3.39 2.74 ...
## $ EqEllipseOblateVolCh1 : num 337 2233 802 725 608 ...
## $ EqEllipseProlateVolCh1 : num 110 1433 583 214 222 ...
## $ EqSphereAreaCh1 : num 742 3279 1727 1195 1140 ...
## $ EqSphereVolCh1 : num 1901 17654 6751 3884 3621 ...
## $ FiberAlign2Ch3 : num 1 1.49 1.3 1.22 1.49 ...
## $ FiberAlign2Ch4 : num 1 1.35 1.52 1.73 1.38 ...
## $ FiberLengthCh1 : num 27 64.3 21.1 43.1 34.7 ...
## $ FiberWidthCh1 : num 7.41 13.17 21.14 7.4 8.48 ...
## $ IntenCoocASMCh3 : num 0.01118 0.02805 0.00686 0.03096 0.02277 ...
## $ IntenCoocASMCh4 : num 0.05045 0.01259 0.00614 0.01103 0.07969 ...
## $ IntenCoocContrastCh3 : num 40.75 8.23 14.45 7.3 15.85 ...
## $ IntenCoocContrastCh4 : num 13.9 6.98 16.7 13.39 3.54 ...
## $ IntenCoocEntropyCh3 : num 7.2 6.82 7.58 6.31 6.78 ...
## $ IntenCoocEntropyCh4 : num 5.25 7.1 7.67 7.2 5.5 ...
## $ IntenCoocMaxCh3 : num 0.0774 0.1532 0.0284 0.1628 0.1274 ...
## $ IntenCoocMaxCh4 : num 0.172 0.0739 0.0232 0.0775 0.2785 ...
## $ KurtIntenCh1 : num -0.6567 -0.2488 -0.2935 0.6259 0.0421 ...
## $ KurtIntenCh3 : num -0.608 -0.331 1.051 0.128 0.952 ...
## $ KurtIntenCh4 : num 0.726 -0.265 0.151 -0.347 -0.195 ...
## $ LengthCh1 : num 26.2 47.2 28.1 37.9 36 ...
## $ NeighborAvgDistCh1 : num 370 174 158 206 205 ...
## $ NeighborMinDistCh1 : num 99.1 30.1 34.9 33.1 27 ...
## $ NeighborVarDistCh1 : num 128 81.4 90.4 116.9 111 ...
## $ PerimCh1 : num 68.8 154.9 84.6 101.1 86.5 ...
## $ ShapeBFRCh1 : num 0.665 0.54 0.724 0.589 0.6 ...
## $ ShapeLWRCh1 : num 2.46 1.47 1.33 2.83 2.73 ...
## $ ShapeP2ACh1 : num 1.88 2.26 1.27 2.55 2.02 ...
## $ SkewIntenCh1 : num 0.455 0.399 0.472 0.882 0.517 ...
## $ SkewIntenCh3 : num 0.46 0.62 0.971 1 1.177 ...
## $ SkewIntenCh4 : num 1.233 0.527 0.325 0.604 0.926 ...
## $ SpotFiberCountCh3 : int 1 4 2 4 1 1 0 2 1 1 ...
## $ SpotFiberCountCh4 : num 5 12 7 8 8 5 5 8 12 8 ...
## $ TotalIntenCh1 : int 2781 24964 11552 5545 6603 53779 43950 4401 7593 6512 ...
## $ TotalIntenCh2 : num 701 160998 47511 28870 30306 ...
## $ TotalIntenCh3 : int 1690 54675 26344 8042 5569 21234 20929 4136 6488 7503 ...
## $ TotalIntenCh4 : int 392 128368 43959 8843 11037 57231 46187 373 24325 23162 ...
## $ VarIntenCh1 : num 12.5 18.8 17.3 13.8 15.4 ...
## $ VarIntenCh3 : num 7.61 56.72 37.67 30.01 20.5 ...
## $ VarIntenCh4 : num 2.71 118.39 49.47 24.75 45.45 ...
## $ WidthCh1 : num 10.6 32.2 21.2 13.4 13.2 ...
## $ XCentroid : int 42 215 371 487 283 191 180 373 236 303 ...
## $ YCentroid : int 14 347 252 295 159 127 138 181 467 468 ...The first column of segmentationData is a unique identifier for each cell and the second column is a factor indicating how the observations were characterized into training and test sets in the original study; these two variables are irrelevant for the purposes of this demonstration and so can be discarded.
The third column Case contains the class labels: PS (poorly-segmented) and WS (well-segmented). Columns 4-61 are the 58 morphological measurements available to be used as predictors. Let’s put the class labels in a vector and the predictors in their own data.frame.
segClass <- segmentationData$Class
segData <- segmentationData[,4:61]5.3.2 Data splitting
Before starting analysis we must partition the data into training and test sets, using the createDataPartition function in caret.
set.seed(42)
trainIndex <- createDataPartition(y=segClass, times=1, p=0.5, list=F)
segDataTrain <- segData[trainIndex,]
segDataTest <- segData[-trainIndex,]
segClassTrain <- segClass[trainIndex]
segClassTest <- segClass[-trainIndex]This results in balanced class distributions within the splits:
summary(segClassTrain)## PS WS
## 650 360summary(segClassTest)## PS WS
## 650 359N.B. The test set is set aside for now. It will be used only ONCE, to test the final model.
5.3.3 Identification of data quality issues
Let’s check our training data set for some undesirable characteristics which may impact model performance and should be addressed through pre-processing.
5.3.3.1 Zero and near zero-variance predictors
The function nearZeroVar identifies predictors that have one unique value. It also diagnoses predictors having both of the following characteristics:
- very few unique values relative to the number of samples
- the ratio of the frequency of the most common value to the frequency of the 2nd most common value is large.
Such zero and near zero-variance predictors have a deleterious impact on modelling and may lead to unstable fits.
nzv <- nearZeroVar(segDataTrain, saveMetrics=T)
nzv## freqRatio percentUnique zeroVar nzv
## AngleCh1 1.000000 100.000000 FALSE FALSE
## AreaCh1 1.083333 37.326733 FALSE FALSE
## AvgIntenCh1 1.000000 100.000000 FALSE FALSE
## AvgIntenCh2 3.000000 99.801980 FALSE FALSE
## AvgIntenCh3 1.000000 100.000000 FALSE FALSE
## AvgIntenCh4 2.000000 99.900990 FALSE FALSE
## ConvexHullAreaRatioCh1 1.000000 98.910891 FALSE FALSE
## ConvexHullPerimRatioCh1 1.000000 100.000000 FALSE FALSE
## DiffIntenDensityCh1 1.000000 100.000000 FALSE FALSE
## DiffIntenDensityCh3 1.000000 100.000000 FALSE FALSE
## DiffIntenDensityCh4 1.000000 100.000000 FALSE FALSE
## EntropyIntenCh1 1.000000 100.000000 FALSE FALSE
## EntropyIntenCh3 1.000000 100.000000 FALSE FALSE
## EntropyIntenCh4 1.000000 100.000000 FALSE FALSE
## EqCircDiamCh1 1.083333 37.326733 FALSE FALSE
## EqEllipseLWRCh1 1.000000 100.000000 FALSE FALSE
## EqEllipseOblateVolCh1 1.000000 100.000000 FALSE FALSE
## EqEllipseProlateVolCh1 1.000000 100.000000 FALSE FALSE
## EqSphereAreaCh1 1.083333 37.326733 FALSE FALSE
## EqSphereVolCh1 1.083333 37.326733 FALSE FALSE
## FiberAlign2Ch3 1.304348 94.950495 FALSE FALSE
## FiberAlign2Ch4 7.285714 94.455446 FALSE FALSE
## FiberLengthCh1 1.000000 95.841584 FALSE FALSE
## FiberWidthCh1 1.000000 95.841584 FALSE FALSE
## IntenCoocASMCh3 1.000000 100.000000 FALSE FALSE
## IntenCoocASMCh4 1.000000 100.000000 FALSE FALSE
## IntenCoocContrastCh3 1.000000 100.000000 FALSE FALSE
## IntenCoocContrastCh4 1.000000 100.000000 FALSE FALSE
## IntenCoocEntropyCh3 1.000000 100.000000 FALSE FALSE
## IntenCoocEntropyCh4 1.000000 100.000000 FALSE FALSE
## IntenCoocMaxCh3 1.250000 94.158416 FALSE FALSE
## IntenCoocMaxCh4 1.250000 94.356436 FALSE FALSE
## KurtIntenCh1 1.000000 100.000000 FALSE FALSE
## KurtIntenCh3 1.000000 100.000000 FALSE FALSE
## KurtIntenCh4 1.000000 100.000000 FALSE FALSE
## LengthCh1 1.000000 100.000000 FALSE FALSE
## NeighborAvgDistCh1 1.000000 100.000000 FALSE FALSE
## NeighborMinDistCh1 1.166667 41.089109 FALSE FALSE
## NeighborVarDistCh1 1.000000 100.000000 FALSE FALSE
## PerimCh1 1.000000 63.762376 FALSE FALSE
## ShapeBFRCh1 1.000000 100.000000 FALSE FALSE
## ShapeLWRCh1 1.000000 100.000000 FALSE FALSE
## ShapeP2ACh1 1.000000 99.801980 FALSE FALSE
## SkewIntenCh1 1.000000 100.000000 FALSE FALSE
## SkewIntenCh3 1.000000 100.000000 FALSE FALSE
## SkewIntenCh4 1.000000 100.000000 FALSE FALSE
## SpotFiberCountCh3 1.212000 1.287129 FALSE FALSE
## SpotFiberCountCh4 1.152778 3.267327 FALSE FALSE
## TotalIntenCh1 1.000000 98.712871 FALSE FALSE
## TotalIntenCh2 1.500000 99.009901 FALSE FALSE
## TotalIntenCh3 1.000000 99.108911 FALSE FALSE
## TotalIntenCh4 1.000000 99.603960 FALSE FALSE
## VarIntenCh1 1.000000 100.000000 FALSE FALSE
## VarIntenCh3 1.000000 100.000000 FALSE FALSE
## VarIntenCh4 1.000000 100.000000 FALSE FALSE
## WidthCh1 1.000000 100.000000 FALSE FALSE
## XCentroid 1.111111 41.584158 FALSE FALSE
## YCentroid 1.000000 35.742574 FALSE FALSE5.3.3.2 Scaling
The variables in this data set are on different scales, for example:
summary(segDataTrain$IntenCoocASMCh4)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.004874 0.017253 0.049458 0.101586 0.121245 0.867845summary(segDataTrain$TotalIntenCh2)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1 15846 49648 53143 72304 362465In this situation it is important to centre and scale each predictor. A predictor variable is centered by subtracting the mean of the predictor from each value. To scale a predictor variable, each value is divided by its standard deviation. After centring and scaling the predictor variable has a mean of 0 and a standard deviation of 1.
5.3.3.3 Skewness
Many of the predictors in the segmentation data set exhibit skewness, i.e. the distribution of their values is asymmetric, for example:
qplot(segDataTrain$IntenCoocASMCh3, binwidth=0.1) +
xlab("IntenCoocASMCh3") +
theme_bw()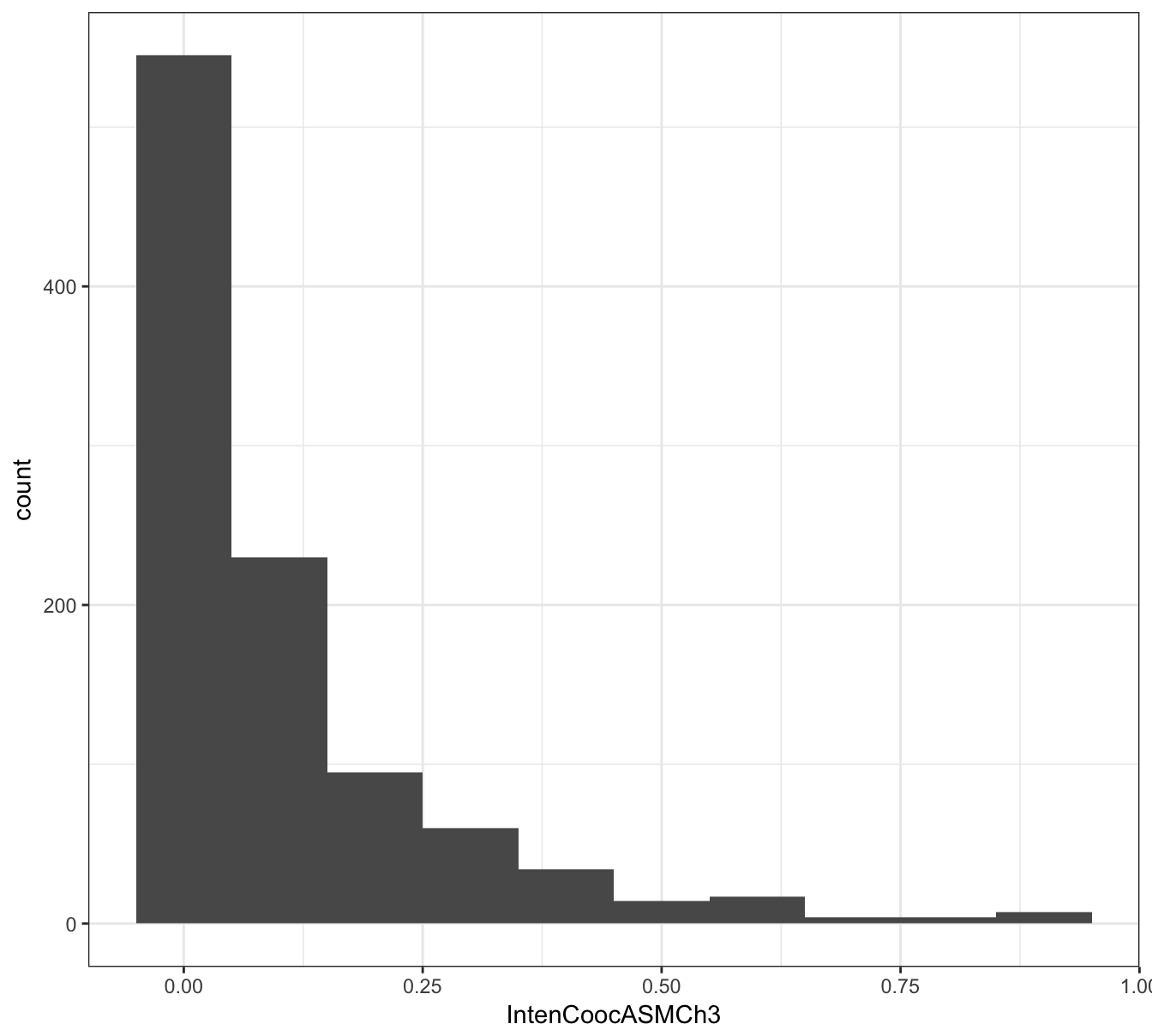
Figure 5.10: Example of a predictor from the segmentation data set showing skewness.
caret provides various methods for transforming skewed variables to normality, including the Box-Cox (Box and Cox 1964) and Yeo-Johnson (Yeo and Johnson 2000) transformations.
5.3.3.4 Correlated predictors
Many of the variables in the segmentation data set are highly correlated.
A correlogram provides a helpful visualization of the patterns of pairwise correlation within the data set.
library(corrplot)
corMat <- cor(segDataTrain)
corrplot(corMat, order="hclust", tl.cex=0.4)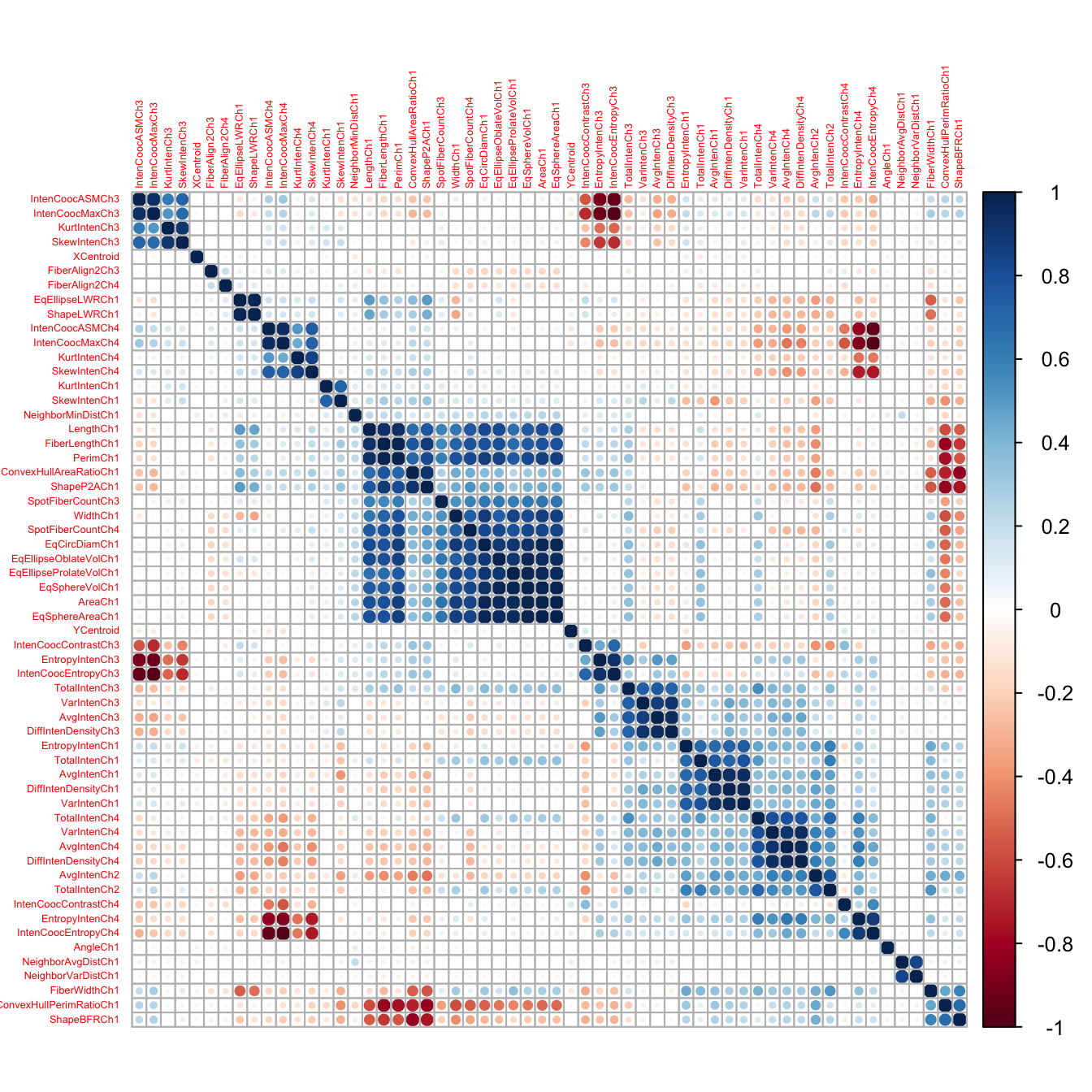
Figure 5.11: Correlogram of the segmentation data set.
The preProcess function in caret has an option, corr to remove highly correlated variables. It considers the absolute values of pair-wise correlations. If two variables are highly correlated, preProcess looks at the mean absolute correlation of each variable and removes the variable with the largest mean absolute correlation.
In the case of data-sets comprised of many highly correlated variables, an alternative to removing correlated predictors is the transformation of the entire data set to a lower dimensional space, using a technique such as principal component analysis (PCA). Methods for dimensionality reduction will be explored in chapter 9.
5.3.4 Fit model without feature selection
Generate a list of seeds.
set.seed(42)
seeds <- vector(mode = "list", length = 26)
for(i in 1:25) seeds[[i]] <- sample.int(1000, 50)
seeds[[26]] <- sample.int(1000,1)Create a list of computational options for resampling. In the interest of speed for this demonstration, we will perform 5-fold cross-validation a total of 5 times. In practice we would use a larger number of folds and repetitions.
train_ctrl <- trainControl(method="repeatedcv",
number = 5,
repeats = 5,
#preProcOptions=list(cutoff=0.75),
seeds = seeds)Create a grid of values of k for evaluation.
tuneParam <- data.frame(k=seq(5,500,10))To deal with the issues of scaling, skewness and highly correlated predictors identified earlier, we need to pre-process the data. We will use the Yeo-Johnson transformation to reduce skewness, because it can deal with the zero values present in some of the predictors. Ideally the pre-processing procedures would be performed within each cross-validation loop, using the following command:
knnFit <- train(segDataTrain, segClassTrain,
method="knn",
preProcess = c("YeoJohnson", "center", "scale", "corr"),
tuneGrid=tuneParam,
trControl=train_ctrl)However, this is time-consuming, so for the purposes of this demonstration we will pre-process the entire training data-set before proceeding with training and cross-validation.
transformations <- preProcess(segDataTrain,
method=c("YeoJohnson", "center", "scale", "corr"),
cutoff=0.75)
segDataTrain <- predict(transformations, segDataTrain)The cutoff refers to the correlation coefficient threshold.
str(segDataTrain)## 'data.frame': 1010 obs. of 27 variables:
## $ AngleCh1 : num 1.045 0.873 -0.376 -0.994 1.586 ...
## $ ConvexHullPerimRatioCh1: num 0.31 -1.221 -0.363 1.22 1.113 ...
## $ EntropyIntenCh1 : num -2.443 -0.671 -1.688 0.554 0.425 ...
## $ EqEllipseOblateVolCh1 : num -0.414 1.693 0.711 -1.817 -1.667 ...
## $ FiberAlign2Ch3 : num -1.8124 0.0933 -0.9679 -0.6188 -0.8721 ...
## $ FiberAlign2Ch4 : num -1.729 -0.331 1.255 -0.291 0.463 ...
## $ FiberWidthCh1 : num -0.776 0.878 -0.779 0.712 0.758 ...
## $ IntenCoocASMCh4 : num -0.368 -0.64 -0.652 -0.665 -0.671 ...
## $ IntenCoocContrastCh3 : num 2.4777 0.0604 -0.0816 0.0634 0.6386 ...
## $ IntenCoocContrastCh4 : num 1.101 0.127 1.046 0.602 1.445 ...
## $ IntenCoocMaxCh3 : num -0.815 -0.232 -0.168 -1.366 -1.37 ...
## $ KurtIntenCh1 : num -0.97 -0.26 0.562 -0.187 0.296 ...
## $ KurtIntenCh3 : num -1.506 -1.133 -0.672 -1.908 -1.491 ...
## $ KurtIntenCh4 : num 0.68398 -0.00329 -0.09737 -0.1679 -0.79044 ...
## $ NeighborAvgDistCh1 : num 2.5376 -1.4791 -0.5357 0.1062 0.0663 ...
## $ NeighborMinDistCh1 : num 3.286 0.289 0.557 -1.679 -1.679 ...
## $ ShapeBFRCh1 : num 0.6733 -0.5448 -0.0649 0.8849 1.4669 ...
## $ ShapeLWRCh1 : num 1.23 -0.351 1.525 -1.832 -1.717 ...
## $ SkewIntenCh1 : num -0.213 -0.297 0.384 -2.41 -2.678 ...
## $ SpotFiberCountCh3 : num -0.366 1.275 1.275 -0.366 -1.573 ...
## $ TotalIntenCh2 : num -1.701 1.682 -0.233 1.107 1.019 ...
## $ VarIntenCh1 : num -2.118 -1.346 -1.917 1.062 0.856 ...
## $ VarIntenCh3 : num -1.9155 -0.1836 -0.8001 0.0478 -0.3658 ...
## $ VarIntenCh4 : num -2.304 0.332 -1.092 0.843 0.387 ...
## $ WidthCh1 : num -1.626 1.845 -0.718 -0.188 -0.333 ...
## $ XCentroid : num -1.647 -0.241 1.484 -0.412 -0.492 ...
## $ YCentroid : num -2.098 1.447 1.118 -0.251 -0.138 ...Perform cross validation to find best value of k.
knnFit <- train(segDataTrain, segClassTrain,
method="knn",
tuneGrid=tuneParam,
trControl=train_ctrl)
knnFit## k-Nearest Neighbors
##
## 1010 samples
## 27 predictor
## 2 classes: 'PS', 'WS'
##
## No pre-processing
## Resampling: Cross-Validated (5 fold, repeated 5 times)
## Summary of sample sizes: 808, 808, 808, 808, 808, 808, ...
## Resampling results across tuning parameters:
##
## k Accuracy Kappa
## 5 0.7883168 0.5449241
## 15 0.7992079 0.5702967
## 25 0.8114851 0.5960169
## 35 0.8033663 0.5780284
## 45 0.8065347 0.5844876
## 55 0.8047525 0.5809689
## 65 0.8097030 0.5903493
## 75 0.8089109 0.5884100
## 85 0.8067327 0.5829885
## 95 0.8059406 0.5798239
## 105 0.8021782 0.5723636
## 115 0.8047525 0.5770621
## 125 0.8011881 0.5681088
## 135 0.8011881 0.5675244
## 145 0.8013861 0.5675697
## 155 0.8031683 0.5703946
## 165 0.8013861 0.5660457
## 175 0.8011881 0.5654292
## 185 0.7996040 0.5610611
## 195 0.7978218 0.5561759
## 205 0.7982178 0.5568515
## 215 0.7972277 0.5539169
## 225 0.7976238 0.5546920
## 235 0.7968317 0.5520418
## 245 0.7968317 0.5517094
## 255 0.7958416 0.5487693
## 265 0.7956436 0.5475332
## 275 0.7958416 0.5467831
## 285 0.7994059 0.5535346
## 295 0.7978218 0.5492166
## 305 0.7984158 0.5488107
## 315 0.7958416 0.5412723
## 325 0.7968317 0.5424166
## 335 0.7908911 0.5264160
## 345 0.7902970 0.5236154
## 355 0.7873267 0.5143268
## 365 0.7861386 0.5101993
## 375 0.7831683 0.5016861
## 385 0.7796040 0.4900167
## 395 0.7778218 0.4836628
## 405 0.7706931 0.4601307
## 415 0.7596040 0.4287823
## 425 0.7489109 0.3946052
## 435 0.7384158 0.3621238
## 445 0.7326733 0.3390919
## 455 0.7251485 0.3140993
## 465 0.7213861 0.2974286
## 475 0.7154455 0.2720747
## 485 0.7091089 0.2460255
## 495 0.7017822 0.2169777
##
## Accuracy was used to select the optimal model using the largest value.
## The final value used for the model was k = 25.plot(knnFit)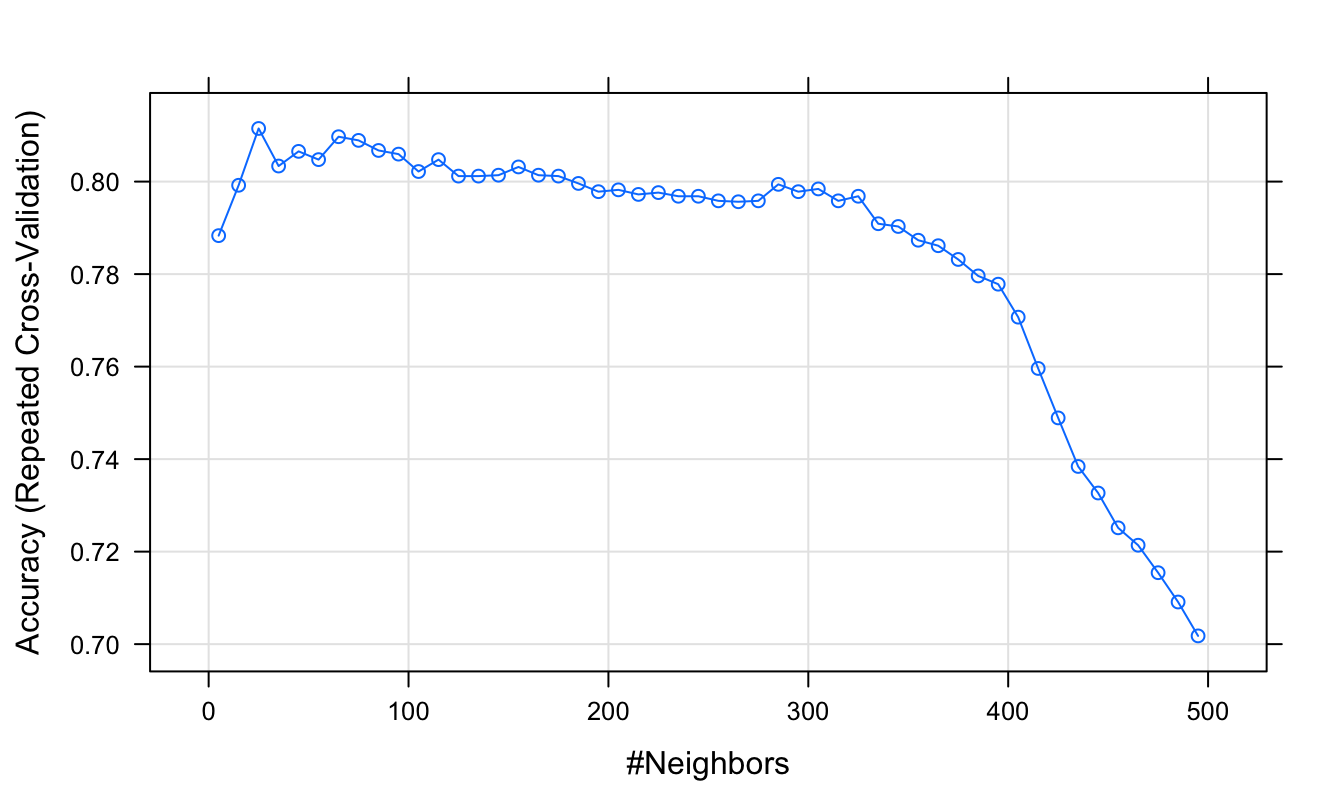
Figure 5.12: Accuracy (repeated cross-validation) as a function of neighbourhood size for the segmentation training data with highly correlated predictors removed.
5.3.5 Feature selection using filter
We will use the same trainingControl settings and tuning grid as before.
train_ctrl <- trainControl(method="repeatedcv",
number = 5,
repeats = 5
)Let’s define a filter using Caret’s Selection By Filter (SBF) function:
mySBF <- caretSBF
mySBF$summary <- twoClassSummaryWe will use a simple t-test to eliminate the predictors that differ the least between classes. Since we are performing many hypothesis tests we will use Holm’s method to control the family wise error rate.
mySBF$score <- function(x, y) {
out <- t.test(x ~ y)$p.value
out <- p.adjust(out, method="holm")
out
}Now to set a p-value threshold for our t-test filter.
mySBF$filter <- function(score, x, y) { score <= 0.01 }Let’s run the cross-validation. The cross-validation will run in two nested loops. Feature selection will occur in the outer loop. Features selected at each iteration of the outer loop will be passed to the inner loop, where the optimum value of k will be found for that set of features.
sbf_ctrl <- sbfControl(functions = mySBF,
method = "repeatedcv",
number = 5,
repeats = 5,
verbose = FALSE)
knn_sbf <- sbf(segDataTrain,
segClassTrain,
trControl = train_ctrl,
sbfControl = sbf_ctrl,
## now arguments to `train`:
method = "knn",
tuneGrid = tuneParam)
knn_sbf##
## Selection By Filter
##
## Outer resampling method: Cross-Validated (5 fold, repeated 5 times)
##
## Resampling performance:
##
## ROC Sens Spec ROCSD SensSD SpecSD
## 0.8831 0.8317 0.7672 0.02275 0.03015 0.06097
##
## Using the training set, 16 variables were selected:
## ConvexHullPerimRatioCh1, EntropyIntenCh1, FiberWidthCh1, IntenCoocASMCh4, IntenCoocContrastCh3...
##
## During resampling, the top 5 selected variables (out of a possible 19):
## ConvexHullPerimRatioCh1 (100%), EntropyIntenCh1 (100%), FiberWidthCh1 (100%), IntenCoocASMCh4 (100%), IntenCoocContrastCh3 (100%)
##
## On average, 15.6 variables were selected (min = 15, max = 17)Much information about the final model is stored in knn_sbf. To reveal the identities of the predictors selected for the final model run:
predictors(knn_sbf)## [1] "ConvexHullPerimRatioCh1" "EntropyIntenCh1"
## [3] "FiberWidthCh1" "IntenCoocASMCh4"
## [5] "IntenCoocContrastCh3" "IntenCoocMaxCh3"
## [7] "KurtIntenCh1" "KurtIntenCh3"
## [9] "KurtIntenCh4" "ShapeBFRCh1"
## [11] "ShapeLWRCh1" "SkewIntenCh1"
## [13] "TotalIntenCh2" "VarIntenCh1"
## [15] "VarIntenCh4" "WidthCh1"Here are some performance metrics for the final model:
knn_sbf$results## ROC Sens Spec ROCSD SensSD SpecSD
## 1 0.8830962 0.8316923 0.7672222 0.02274574 0.03014757 0.06097417To retrieve the optimum value of k found during training run:
knn_sbf$fit$finalModel$k## [1] 25Let’s predict our test set using our final model.
segDataTest <- predict(transformations, segDataTest)
test_pred <- predict(knn_sbf, segDataTest)
confusionMatrix(test_pred$pred, segClassTest)## Confusion Matrix and Statistics
##
## Reference
## Prediction PS WS
## PS 543 98
## WS 107 261
##
## Accuracy : 0.7968
## 95% CI : (0.7707, 0.8213)
## No Information Rate : 0.6442
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.5593
## Mcnemar's Test P-Value : 0.5763
##
## Sensitivity : 0.8354
## Specificity : 0.7270
## Pos Pred Value : 0.8471
## Neg Pred Value : 0.7092
## Prevalence : 0.6442
## Detection Rate : 0.5382
## Detection Prevalence : 0.6353
## Balanced Accuracy : 0.7812
##
## 'Positive' Class : PS
## 5.4 Regression
k-nn can also be applied to the problem of regression as we will see in the following example. The BloodBrain dataset in the caret package contains data on 208 chemical compounds, organized in two objects:
- logBBB - a vector of the log ratio of the concentration of a chemical compound in the brain and the concentration in the blood.
- bbbDescr - a data frame of 134 molecular descriptors of the compounds.
We’ll start by loading the data.
data(BloodBrain)
str(bbbDescr)## 'data.frame': 208 obs. of 134 variables:
## $ tpsa : num 12 49.3 50.5 37.4 37.4 ...
## $ nbasic : int 1 0 1 0 1 1 1 1 1 1 ...
## $ negative : int 0 0 0 0 0 0 0 0 0 0 ...
## $ vsa_hyd : num 167.1 92.6 295.2 319.1 299.7 ...
## $ a_aro : int 0 6 15 15 12 11 6 12 12 6 ...
## $ weight : num 156 151 366 383 326 ...
## $ peoe_vsa.0 : num 76.9 38.2 58.1 62.2 74.8 ...
## $ peoe_vsa.1 : num 43.4 25.5 124.7 124.7 118 ...
## $ peoe_vsa.2 : num 0 0 21.7 13.2 33 ...
## $ peoe_vsa.3 : num 0 8.62 8.62 21.79 0 ...
## $ peoe_vsa.4 : num 0 23.3 17.4 0 0 ...
## $ peoe_vsa.5 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ peoe_vsa.6 : num 17.24 0 8.62 8.62 8.62 ...
## $ peoe_vsa.0.1 : num 18.7 49 83.8 83.8 83.8 ...
## $ peoe_vsa.1.1 : num 43.5 0 49 68.8 36.8 ...
## $ peoe_vsa.2.1 : num 0 0 0 0 0 ...
## $ peoe_vsa.3.1 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ peoe_vsa.4.1 : num 0 0 5.68 5.68 5.68 ...
## $ peoe_vsa.5.1 : num 0 13.567 2.504 0 0.137 ...
## $ peoe_vsa.6.1 : num 0 7.9 2.64 2.64 2.5 ...
## $ a_acc : int 0 2 2 2 2 2 2 2 0 2 ...
## $ a_acid : int 0 0 0 0 0 0 0 0 0 0 ...
## $ a_base : int 1 0 1 1 1 1 1 1 1 1 ...
## $ vsa_acc : num 0 13.57 8.19 8.19 8.19 ...
## $ vsa_acid : num 0 0 0 0 0 0 0 0 0 0 ...
## $ vsa_base : num 5.68 0 0 0 0 ...
## $ vsa_don : num 5.68 5.68 5.68 5.68 5.68 ...
## $ vsa_other : num 0 28.1 43.6 28.3 19.6 ...
## $ vsa_pol : num 0 13.6 0 0 0 ...
## $ slogp_vsa0 : num 18 25.4 14.1 14.1 14.1 ...
## $ slogp_vsa1 : num 0 23.3 34.8 34.8 34.8 ...
## $ slogp_vsa2 : num 3.98 23.86 0 0 0 ...
## $ slogp_vsa3 : num 0 0 76.2 76.2 76.2 ...
## $ slogp_vsa4 : num 4.41 0 3.19 3.19 3.19 ...
## $ slogp_vsa5 : num 32.9 0 9.51 0 0 ...
## $ slogp_vsa6 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ slogp_vsa7 : num 0 70.6 148.1 144 140.7 ...
## $ slogp_vsa8 : num 113.2 0 75.5 75.5 75.5 ...
## $ slogp_vsa9 : num 33.3 41.3 28.3 55.5 26 ...
## $ smr_vsa0 : num 0 23.86 12.63 3.12 3.12 ...
## $ smr_vsa1 : num 18 25.4 27.8 27.8 27.8 ...
## $ smr_vsa2 : num 4.41 0 0 0 0 ...
## $ smr_vsa3 : num 3.98 5.24 8.43 8.43 8.43 ...
## $ smr_vsa4 : num 0 20.8 29.6 21.4 20.3 ...
## $ smr_vsa5 : num 113.2 70.6 235.1 235.1 234.6 ...
## $ smr_vsa6 : num 0 5.26 76.25 76.25 76.25 ...
## $ smr_vsa7 : num 66.2 33.3 0 31.3 0 ...
## $ tpsa.1 : num 16.6 49.3 51.7 38.6 38.6 ...
## $ logp.o.w. : num 2.948 0.889 4.439 5.254 3.8 ...
## $ frac.anion7. : num 0 0.001 0 0 0 0 0.001 0 0 0 ...
## $ frac.cation7. : num 0.999 0 0.986 0.986 0.986 0.986 0.996 0.946 0.999 0.976 ...
## $ andrewbind : num 3.4 -3.3 12.8 12.8 10.3 10 10.4 15.9 12.9 9.5 ...
## $ rotatablebonds : int 3 2 8 8 8 8 8 7 4 5 ...
## $ mlogp : num 2.5 1.06 4.66 3.82 3.27 ...
## $ clogp : num 2.97 0.494 5.137 5.878 4.367 ...
## $ mw : num 155 151 365 382 325 ...
## $ nocount : int 1 3 5 4 4 4 4 3 2 4 ...
## $ hbdnr : int 1 2 1 1 1 1 2 1 1 0 ...
## $ rule.of.5violations : int 0 0 1 1 0 0 0 0 1 0 ...
## $ alert : int 0 0 0 0 0 0 0 0 0 0 ...
## $ prx : int 0 1 6 2 2 2 1 0 0 4 ...
## $ ub : num 0 3 5.3 5.3 4.2 3.6 3 4.7 4.2 3 ...
## $ pol : int 0 2 3 3 2 2 2 3 4 1 ...
## $ inthb : int 0 0 0 0 0 0 1 0 0 0 ...
## $ adistm : num 0 395 1365 703 746 ...
## $ adistd : num 0 10.9 25.7 10 10.6 ...
## $ polar_area : num 21.1 117.4 82.1 65.1 66.2 ...
## $ nonpolar_area : num 379 248 638 668 602 ...
## $ psa_npsa : num 0.0557 0.4743 0.1287 0.0974 0.11 ...
## $ tcsa : num 0.0097 0.0134 0.0111 0.0108 0.0118 0.0111 0.0123 0.0099 0.0106 0.0115 ...
## $ tcpa : num 0.1842 0.0417 0.0972 0.1218 0.1186 ...
## $ tcnp : num 0.0103 0.0198 0.0125 0.0119 0.013 0.0125 0.0162 0.011 0.0109 0.0122 ...
## $ ovality : num 1.1 1.12 1.3 1.3 1.27 ...
## $ surface_area : num 400 365 720 733 668 ...
## $ volume : num 656 555 1224 1257 1133 ...
## $ most_negative_charge: num -0.617 -0.84 -0.801 -0.761 -0.857 ...
## $ most_positive_charge: num 0.307 0.497 0.541 0.48 0.455 ...
## $ sum_absolute_charge : num 3.89 4.89 7.98 7.93 7.85 ...
## $ dipole_moment : num 1.19 4.21 3.52 3.15 3.27 ...
## $ homo : num -9.67 -8.96 -8.63 -8.56 -8.67 ...
## $ lumo : num 3.4038 0.1942 0.0589 -0.2651 0.3149 ...
## $ hardness : num 6.54 4.58 4.34 4.15 4.49 ...
## $ ppsa1 : num 349 223 518 508 509 ...
## $ ppsa2 : num 679 546 2066 2013 1999 ...
## $ ppsa3 : num 31 42.3 64 61.7 61.6 ...
## $ pnsa1 : num 51.1 141.8 202 225.4 158.8 ...
## $ pnsa2 : num -99.3 -346.9 -805.9 -894 -623.3 ...
## $ pnsa3 : num -10.5 -44 -43.8 -42 -39.8 ...
## $ fpsa1 : num 0.872 0.611 0.719 0.693 0.762 ...
## $ fpsa2 : num 1.7 1.5 2.87 2.75 2.99 ...
## $ fpsa3 : num 0.0774 0.1159 0.0888 0.0842 0.0922 ...
## $ fnsa1 : num 0.128 0.389 0.281 0.307 0.238 ...
## $ fnsa2 : num -0.248 -0.951 -1.12 -1.22 -0.933 ...
## $ fnsa3 : num -0.0262 -0.1207 -0.0608 -0.0573 -0.0596 ...
## $ wpsa1 : num 139.7 81.4 372.7 372.1 340.1 ...
## $ wpsa2 : num 272 199 1487 1476 1335 ...
## $ wpsa3 : num 12.4 15.4 46 45.2 41.1 ...
## $ wnsa1 : num 20.4 51.8 145.4 165.3 106 ...
## $ wnsa2 : num -39.8 -126.6 -580.1 -655.3 -416.3 ...
## [list output truncated]str(logBBB)## num [1:208] 1.08 -0.4 0.22 0.14 0.69 0.44 -0.43 1.38 0.75 0.88 ...Evidently the variables are on different scales which is problematic for k-nn.
5.4.1 Partition data
Before proceeding the data set must be partitioned into a training and a test set.
set.seed(42)
trainIndex <- createDataPartition(y=logBBB, times=1, p=0.8, list=F)
descrTrain <- bbbDescr[trainIndex,]
concRatioTrain <- logBBB[trainIndex]
descrTest <- bbbDescr[-trainIndex,]
concRatioTest <- logBBB[-trainIndex]5.4.2 Data pre-processing
Are there any issues with the data that might affect model fitting? Let’s start by considering correlation.
cm <- cor(descrTrain)
corrplot(cm, order="hclust", tl.pos="n")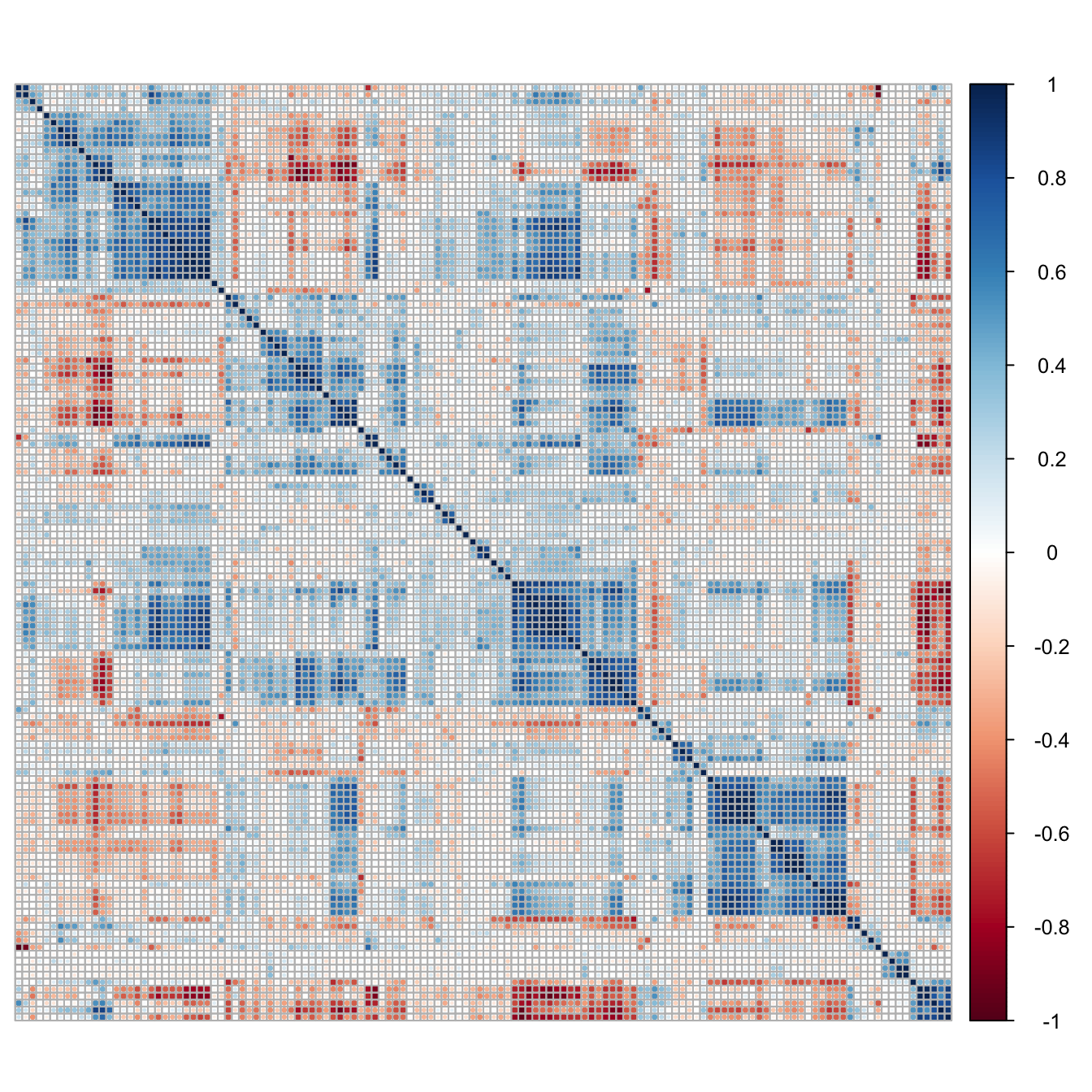
Figure 5.13: Correlogram of the chemical compound descriptors.
The number of variables exhibiting a pair-wise correlation coefficient above 0.75 can be determined:
highCorr <- findCorrelation(cm, cutoff=0.75)
length(highCorr)## [1] 68A check for the presence of missing values:
anyNA(descrTrain)## [1] FALSEDetection of near zero variance predictors:
nearZeroVar(descrTrain)## [1] 3 16 22 25 50 60We know there are issues with scaling, and the presence of highly correlated predictors and near zero variance predictors. These problems are resolved by pre-processing. First we define the procesing steps.
transformations <- preProcess(descrTrain,
method=c("center", "scale", "corr", "nzv"),
cutoff=0.75)Then this transformation can be applied to the compound descriptor data set.
descrTrain <- predict(transformations, descrTrain)5.4.3 Search for optimum k
The optimum value of k can be found by cross-validation, following similar methodology to that used to find the best k for classification. We’ll start by generating seeds to make this example reproducible.
set.seed(42)
seeds <- vector(mode = "list", length = 26)
for(i in 1:25) seeds[[i]] <- sample.int(1000, 10)
seeds[[26]] <- sample.int(1000,1)Ten values of k will be evaluated using 5 repeats of 5-fold cross-validation.
knnTune <- train(descrTrain,
concRatioTrain,
method="knn",
tuneGrid = data.frame(.k=1:10),
trControl = trainControl(method="repeatedcv",
number = 5,
repeats = 5,
seeds=seeds,
preProcOptions=list(cutoff=0.75))
)
knnTune## k-Nearest Neighbors
##
## 168 samples
## 61 predictor
##
## No pre-processing
## Resampling: Cross-Validated (5 fold, repeated 5 times)
## Summary of sample sizes: 135, 134, 136, 134, 133, 135, ...
## Resampling results across tuning parameters:
##
## k RMSE Rsquared MAE
## 1 0.6520387 0.3985028 0.4632774
## 2 0.6113262 0.4259039 0.4627144
## 3 0.5862976 0.4444624 0.4402393
## 4 0.5828015 0.4437783 0.4407852
## 5 0.5933604 0.4209923 0.4516132
## 6 0.5982192 0.4100908 0.4550370
## 7 0.6032227 0.4002708 0.4531828
## 8 0.6078117 0.3936972 0.4583254
## 9 0.6106399 0.3858548 0.4596576
## 10 0.6149638 0.3799661 0.4629568
##
## RMSE was used to select the optimal model using the smallest value.
## The final value used for the model was k = 4.The Root Mean Squared Error (RMSE) measures the differences between the values predicted by the model and the values actually observed. More specifically, it represents the sample standard deviation of the difference between the predicted values and observed values.
plot(knnTune)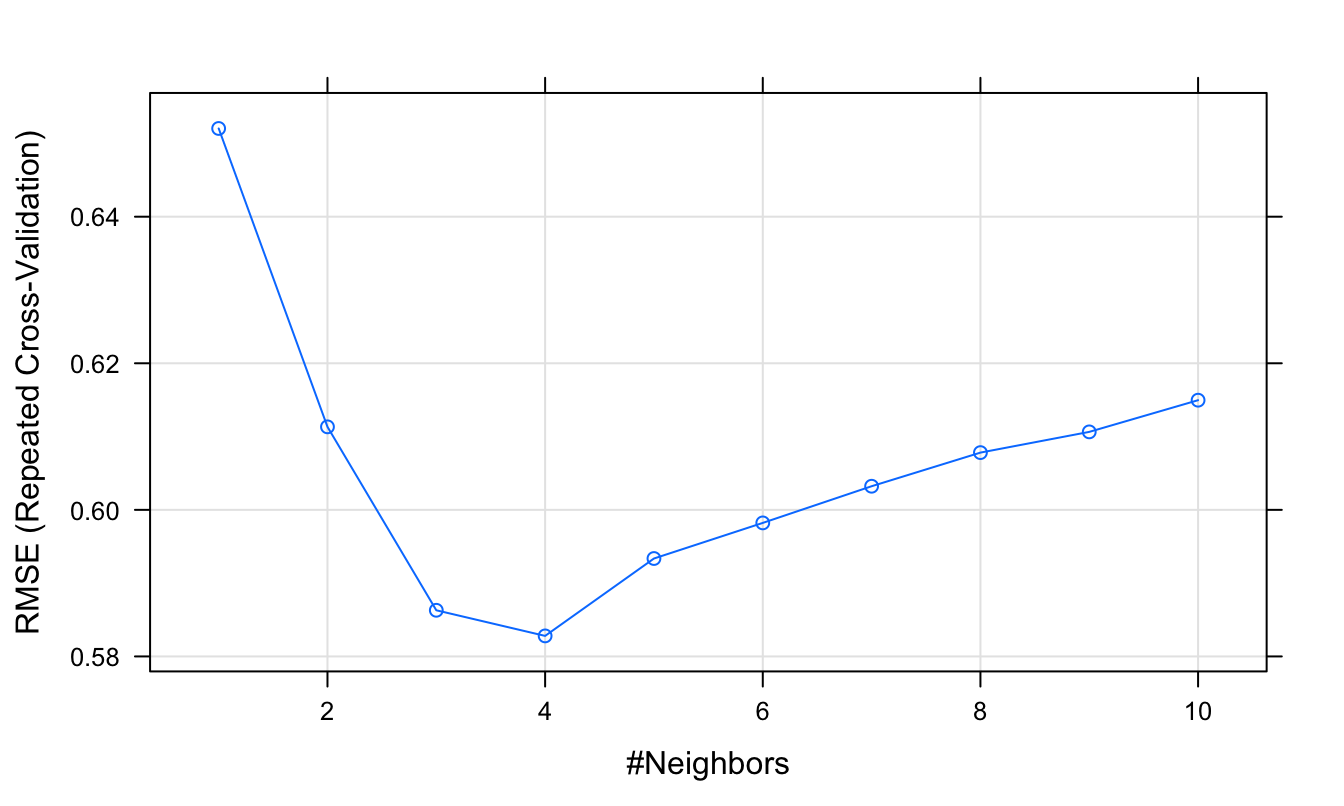
Figure 5.14: Root Mean Squared Error as a function of neighbourhood size.
5.4.4 Use model to make predictions
Before attempting to predict the blood/brain concentration ratios of the test samples, the descriptors in the test set must be transformed using the same pre-processing procedure that was applied to the descriptors in the training set.
descrTest <- predict(transformations, descrTest)Use model to predict outcomes (concentration ratios) of the test set.
test_pred <- predict(knnTune, descrTest)Prediction performance can be visualized in a scatterplot.
qplot(concRatioTest, test_pred) +
xlab("observed") +
ylab("predicted") +
theme_bw()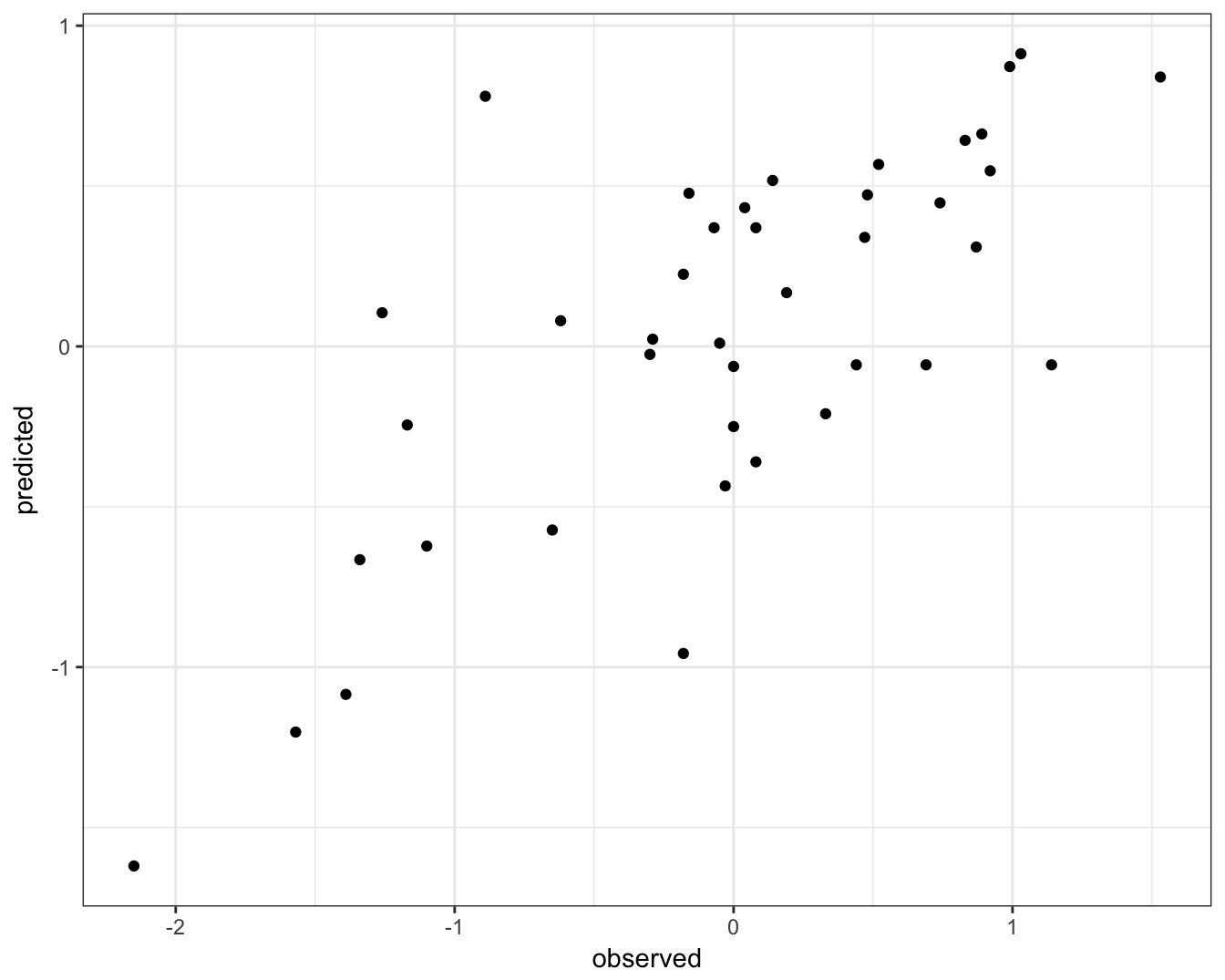
Figure 5.15: Concordance between observed concentration ratios and those predicted by k-nn regression.
We can also measure correlation between observed and predicted values.
cor(concRatioTest, test_pred)## [1] 0.72780345.5 Exercises
5.5.1 Exercise 1
The seeds data set https://archive.ics.uci.edu/ml/datasets/seeds contains morphological measurements on the kernels of three varieties of wheat: Kama, Rosa and Canadian.
Load the data into your R session using:
load("data/wheat_seeds/wheat_seeds.Rda")The data are split into two objects. morphometrics is a data.frame containing the morphological measurements:
str(morphometrics)## 'data.frame': 210 obs. of 7 variables:
## $ area : num 15.3 14.9 14.3 13.8 16.1 ...
## $ perimeter : num 14.8 14.6 14.1 13.9 15 ...
## $ compactness : num 0.871 0.881 0.905 0.895 0.903 ...
## $ kernLength : num 5.76 5.55 5.29 5.32 5.66 ...
## $ kernWidth : num 3.31 3.33 3.34 3.38 3.56 ...
## $ asymCoef : num 2.22 1.02 2.7 2.26 1.35 ...
## $ grooveLength: num 5.22 4.96 4.83 4.8 5.17 ...variety is a factor containing the corresponding classes:
str(variety)## Factor w/ 3 levels "Canadian","Kama",..: 2 2 2 2 2 2 2 2 2 2 ...Your task is to build a k-nn classifier which will predict the variety of wheat from a seeds morphological measurements. You do not need to perform feature selection, but you will want to pre-process the data.
Solutions to exercises can be found in appendix D.
References
Kuhn, Max, and Kjell Johnson. 2013. Applied Predictive Modeling. New York: Springer.
Hill, Andrew A., Peter LaPan, Yizheng Li, and Steve Haney. 2007. “Impact of Image Segmentation on High-Content Screening Data Quality for Sk-Br-3 Cells.” BMC Bioinformatics 8 (1): 340. doi:10.1186/1471-2105-8-340.
Box, G. E. P., and D. R. Cox. 1964. “An analysis of transformations (with discussion).” Journal of the Royal Statistical Society B 26: 211–52.
Yeo, I. K., and R. Johnson. 2000. “A new family of power transformations to improve normality or symmetry.” Biometrika 87: 954–59.