7 Decision trees and random forests
7.1 Decision Trees
What is a Decision Tree?
Decision tree or recursive partitioning is a supervised graph based algorithm to represent choices and the results of the choices in the form of a tree.
The nodes in the graph represent an event or choice and it is referred to as a leaf and the set of decisions made at the node is reffered to as branches.
Decision trees map non-linear relationships and the hierarchial leaves and branches makes a Tree.
It is one of the most widely used tool in ML for predictive analytics. Examples of use of decision tress are − predicting an email as spam or not spam, predicting whether a tumor is cancerous or not.
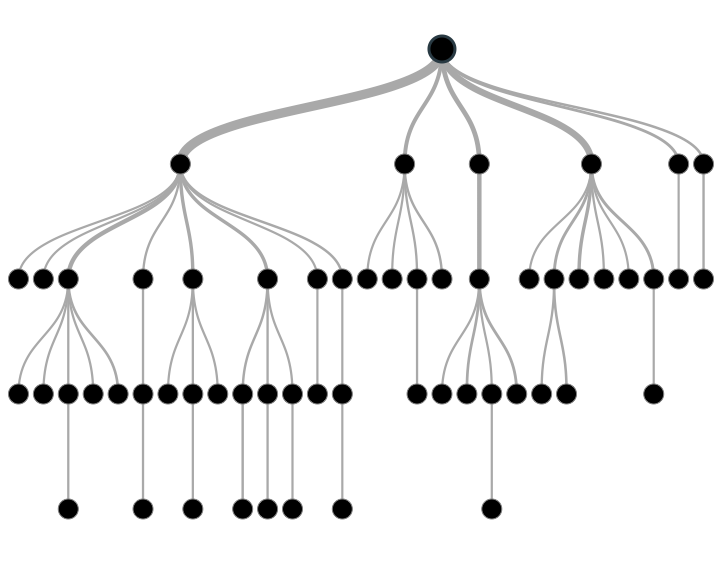
Figure 7.1: Decision Tree
Image source: analyticsvidhya.com
How does it work?
A model is first created with training data and then a set of validation data is used to verify and improve the model. R has many packages, such as ctree, rpart, tree, and so on, which are used to create and visualize decision trees.
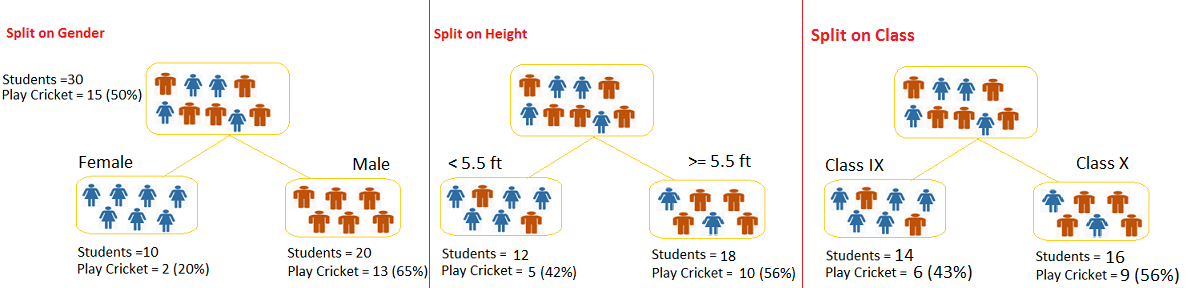
Figure 7.2: Example of a decision Tree
Image source: analyticsvidhya.com
Example of a decision tree
In this problem (Figure 6.2), we need to segregate students who play cricket in their leisure time based on highly significant input variable among all three.
The decision tree algorithm will initially segregate the students based on all values of three variable (Gender, Class, and Height) and identify the variable, which creates the best homogeneous sets of students (which are heterogeneous to each other).
In the snapshot above, you can see that variable Gender is able to identify best homogeneous sets compared to the other two variables.
There are a number of decision tree algorithms. We have to choose them based on our dataset. If the dependent variable is categorical, then we have to use a categorical variable decision tree. If the dependent variable is continuous, then we have to use a continuos variable deicsion tree.
The above example is of the categorical variable decision tree type.
A simple R code for decision tree looks like this:
library(rpart)
x <- cbind(x_train,y_train)
# grow tree fit <- rpart(y_train ~ ., data = x,method=“class”)
summary(fit)
#Predict Output predicted= predict(fit,x_test)
Where:
y_train – represents dependent variable.
x_train – represents independent variable
x – represents training data.
Terminologies related to decision trees
Root nodule: the entire population that can get further divided into homogenous sets
Splitting: process of diving a node into two or more sub-nodes
Decision node: When a sub-node splits into further sub-nodes
Leaf or terminal node: when a node does not split further it is called a terminal node.
Prunning: A loose stopping crieteria is used to contruct the tree and then the tree is cut back by removing branches that do not contribute to the generalisation accuracy.
Branch: a sub-section of an entire tree
How does a tree decide where to split?
The classification tree searches through each dependent variable to find a single variable that splits the data into two or more groups and this process is repeated until the stopping criteria is invoked.
The decision of making strategic splits heavily affects a tree’s accuracy. The decision criteria is different for classification and regression trees.
Decision trees use multiple algorithms to decide to split a node in two or more sub-nodes. The common goal for these algorithms is the creation of sub-nodes with increased homogeneity. In other words, we can say that purity of the node increases with respect to the target variable. Decision tree splits the nodes on all available variables and then selects the split which results in most homogeneous sub-nodes.
Commonly used algorithms to decide where to split
Gini Index
If we select two items from a population at random then they must be of same class and the probability for this is 1 if population is pure.
- It works with categorical target variable “Success” or “Failure”.
- It performs only Binary splits
- Higher the value of Gini higher the homogeneity.
- CART (Classification and Regression Tree) uses Gini method to create binary splits.
Step 1: Calculate Gini for sub-nodes, using formula sum of square of probability for success and failure \[p^2+q^2\]. Step 2: Calculate Gini for split using weighted Gini score of each node of that split.
Chi-Square
It is an algorithm to find out the statistical significance between the differences between sub-nodes and parent node. We measure it by sum of squares of standardized differences between observed and expected frequencies of target variable.
- It works with categorical target variable “Success” or “Failure”.
- It can perform two or more splits.
- Higher the value of Chi-Square higher the statistical significance of differences between sub-node and Parent node.
- Chi-Square of each node is calculated using formula, Chi-square = \[\sum(Actual – Expected)^2 / Expected\]
Steps to Calculate Chi-square for a split:
- Calculate Chi-square for individual node by calculating the deviation for Success and Failure both
- Calculated Chi-square of Split using Sum of all Chi-square of success and Failure of each node of the split
Information Gain
The more homogenous something is the less information is needed to describe it and hence it has gained information. Information theory has a measure to define this degree of disorganization in a system and it is known as Entropy. If a sample is completely homogeneous, then the entropy is zero and if it is equally divided (50% – 50%), it has entropy of one.
Entropy can be calculated using formula \[Entropy = -plog_2p - qlog_2q\]
Where p and q are probablity of success and failure
Reduction in Variance
Reduction in variance is an algorithm used for continuous target variables (regression problems). This algorithm uses the standard formula of variance to choose the best split. The split with lower variance is selected as the criteria to split the population:
Advantages of decision tree
- Simple to understand and use
- Algorithms are robust to noisy data
- Useful in data exploration
- decision tree is ‘non parametric’ in nature i.e. does not have any assumptions about the distribution of the variables
Disadvantages of decision tree
1.Overfitting is the common disadvantage of decision trees. It is taken care of partially by constraining the model parameter and by prunning.
2. It is not ideal for continuous variables as in it looses information
Some parameters used to defining a tree and constrain overfitting
- Minimum sample for a node split
- Minimum sample for a terminal node
- Maximum depth of a tree
- Maximum number of terminal nodes
- Maximum features considered for split
Acknowledgement: some aspects of this explanation can be read from www.analyticsvidhya.com
Example code with categorical data
We are going to plot a car evaulation data with 7 attributes, 6 as feature attributes and 1 as the target attribute. This is to evaluate what kinds of cars people purchase. All the attributes are categorical. We will try to build a classifier for predicting the Class attribute. The index of target attribute is 7th.
instaling packages and downloading data
R package caret helps to perform various machine learning tasks including decision tree classification. The rplot.plot package will help to get a visual plot of the decision tree.
library(caret)## Loading required package: lattice## Loading required package: ggplot2library(rpart.plot)## Loading required package: rpartdata_url <- c("https://archive.ics.uci.edu/ml/machine-learning-databases/car/car.data")
download.file(url = data_url, destfile = "car.data")
car_df <- read.csv("car.data", sep = ',', header = FALSE) str(car_df)## 'data.frame': 1728 obs. of 7 variables:
## $ V1: Factor w/ 4 levels "high","low","med",..: 4 4 4 4 4 4 4 4 4 4 ...
## $ V2: Factor w/ 4 levels "high","low","med",..: 4 4 4 4 4 4 4 4 4 4 ...
## $ V3: Factor w/ 4 levels "2","3","4","5more": 1 1 1 1 1 1 1 1 1 1 ...
## $ V4: Factor w/ 3 levels "2","4","more": 1 1 1 1 1 1 1 1 1 2 ...
## $ V5: Factor w/ 3 levels "big","med","small": 3 3 3 2 2 2 1 1 1 3 ...
## $ V6: Factor w/ 3 levels "high","low","med": 2 3 1 2 3 1 2 3 1 2 ...
## $ V7: Factor w/ 4 levels "acc","good","unacc",..: 3 3 3 3 3 3 3 3 3 3 ...The output of this will show us that our dataset consists of 1728 observations each with 7 attributes.
head(car_df)## V1 V2 V3 V4 V5 V6 V7
## 1 vhigh vhigh 2 2 small low unacc
## 2 vhigh vhigh 2 2 small med unacc
## 3 vhigh vhigh 2 2 small high unacc
## 4 vhigh vhigh 2 2 med low unacc
## 5 vhigh vhigh 2 2 med med unacc
## 6 vhigh vhigh 2 2 med high unaccAll the features are categorical, so normalization of data is not needed.
Data Slicing
Data slicing is a step to split data into train and test set. Training data set can be used specifically for our model building. Test dataset should not be mixed up while building model. Even during standardization, we should not standardize our test set.
set.seed(3033)
intrain <- createDataPartition(y = car_df$V1, p= 0.7, list = FALSE)
training <- car_df[intrain,]
testing <- car_df[-intrain,]The “p” parameter holds a decimal value in the range of 0-1. It’s to show that percentage of the split. We are using p=0.7. It means that data split should be done in 70:30 ratio.
Data Preprocessing
#check dimensions of train & test set
dim(training); dim(testing);## [1] 1212 7## [1] 516 7anyNA(car_df)## [1] FALSEsummary(car_df)## V1 V2 V3 V4 V5 V6
## high :432 high :432 2 :432 2 :576 big :576 high:576
## low :432 low :432 3 :432 4 :576 med :576 low :576
## med :432 med :432 4 :432 more:576 small:576 med :576
## vhigh:432 vhigh:432 5more:432
## V7
## acc : 384
## good : 69
## unacc:1210
## vgood: 65Training the Decision Tree classifier with criterion as INFORMATION GAIN
trctrl <- trainControl(method = "repeatedcv", number = 10, repeats = 3)
set.seed(3333)
dtree_fit <- train(V7 ~., data = training, method = "rpart",
parms = list(split = "information"),
trControl=trctrl,
tuneLength = 10)Trained Decision Tree classifier results
dtree_fit ## CART
##
## 1212 samples
## 6 predictors
## 4 classes: 'acc', 'good', 'unacc', 'vgood'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 1091, 1090, 1091, 1092, 1090, 1091, ...
## Resampling results across tuning parameters:
##
## cp Accuracy Kappa
## 0.01123596 0.8655218 0.7104756
## 0.01404494 0.8547504 0.6850294
## 0.01896067 0.8380018 0.6444074
## 0.01966292 0.8352468 0.6390441
## 0.02247191 0.8168367 0.6035238
## 0.02387640 0.8151860 0.6002291
## 0.05337079 0.7802250 0.5541888
## 0.06179775 0.7741710 0.5466629
## 0.07584270 0.7524613 0.4213615
## 0.08426966 0.7164441 0.1425639
##
## Accuracy was used to select the optimal model using the largest value.
## The final value used for the model was cp = 0.01123596.Plotting the decision tress
prp(dtree_fit$finalModel, box.palette = "Reds", tweak = 1.2)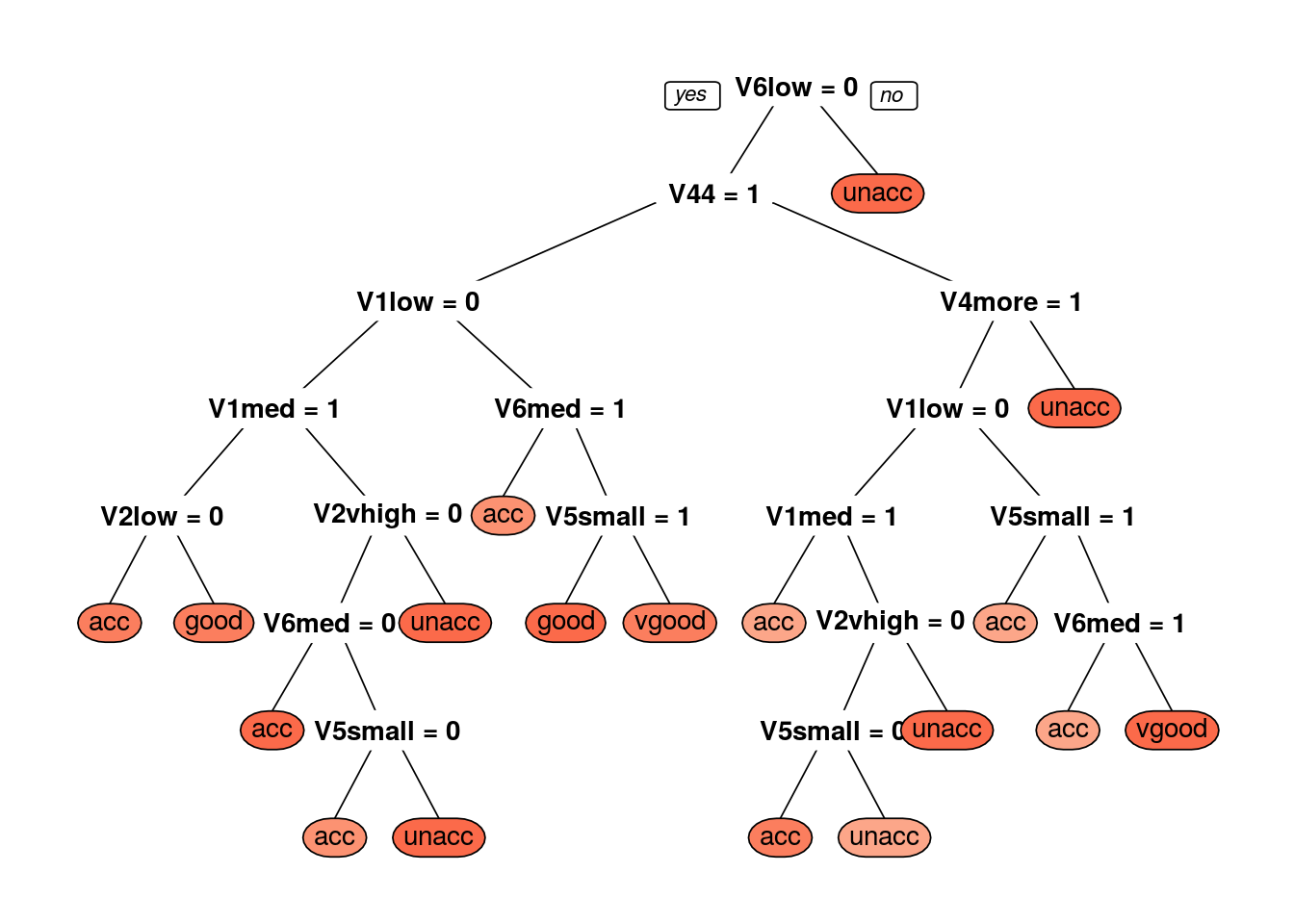
Prediction
The model is trained with cp = 0.01123596. cp is complexity parameter for our dtree. We are ready to predict classes for our test set. We can use predict() method. Let’s try to predict target variable for test set’s 1st record.
testing[1,]## V1 V2 V3 V4 V5 V6 V7
## 2 vhigh vhigh 2 2 small med unaccpredict(dtree_fit, newdata = testing[1,])## [1] unacc
## Levels: acc good unacc vgoodFor our 1st record of testing data classifier is predicting class variable as “unacc”. Now, its time to predict target variable for the whole test set.
test_pred <- predict(dtree_fit, newdata = testing)
confusionMatrix(test_pred, testing$V7 ) #check accuracy## Confusion Matrix and Statistics
##
## Reference
## Prediction acc good unacc vgood
## acc 102 19 36 3
## good 6 4 0 3
## unacc 5 0 318 0
## vgood 11 1 0 8
##
## Overall Statistics
##
## Accuracy : 0.8372
## 95% CI : (0.8025, 0.868)
## No Information Rate : 0.686
## P-Value [Acc > NIR] : 3.262e-15
##
## Kappa : 0.6703
## Mcnemar's Test P-Value : NA
##
## Statistics by Class:
##
## Class: acc Class: good Class: unacc Class: vgood
## Sensitivity 0.8226 0.166667 0.8983 0.57143
## Specificity 0.8520 0.981707 0.9691 0.97610
## Pos Pred Value 0.6375 0.307692 0.9845 0.40000
## Neg Pred Value 0.9382 0.960239 0.8135 0.98790
## Prevalence 0.2403 0.046512 0.6860 0.02713
## Detection Rate 0.1977 0.007752 0.6163 0.01550
## Detection Prevalence 0.3101 0.025194 0.6260 0.03876
## Balanced Accuracy 0.8373 0.574187 0.9337 0.77376The above results show that the classifier with the criterion as information gain is giving 83.72% of accuracy for the test set.
Training the Decision Tree classifier with criterion as GINI INDEX
Let’s try to program a decision tree classifier using splitting criterion as gini index.
set.seed(3333)
dtree_fit_gini <- train(V7 ~., data = training, method = "rpart",
parms = list(split = "gini"),
trControl=trctrl,
tuneLength = 10)
dtree_fit_gini## CART
##
## 1212 samples
## 6 predictors
## 4 classes: 'acc', 'good', 'unacc', 'vgood'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 1091, 1090, 1091, 1092, 1090, 1091, ...
## Resampling results across tuning parameters:
##
## cp Accuracy Kappa
## 0.01123596 0.8603075 0.6980952
## 0.01404494 0.8528534 0.6797153
## 0.01896067 0.8176967 0.5885188
## 0.01966292 0.8143977 0.5818006
## 0.02247191 0.7939998 0.5391064
## 0.02387640 0.7923469 0.5378897
## 0.05337079 0.7824472 0.5363813
## 0.06179775 0.7744555 0.5368891
## 0.07584270 0.7524613 0.4213615
## 0.08426966 0.7164441 0.1425639
##
## Accuracy was used to select the optimal model using the largest value.
## The final value used for the model was cp = 0.01123596.It is showing us the accuracy metrics for different values of cp.
Plotting decision tree
prp(dtree_fit_gini$finalModel, box.palette = "Blues", tweak = 1.2)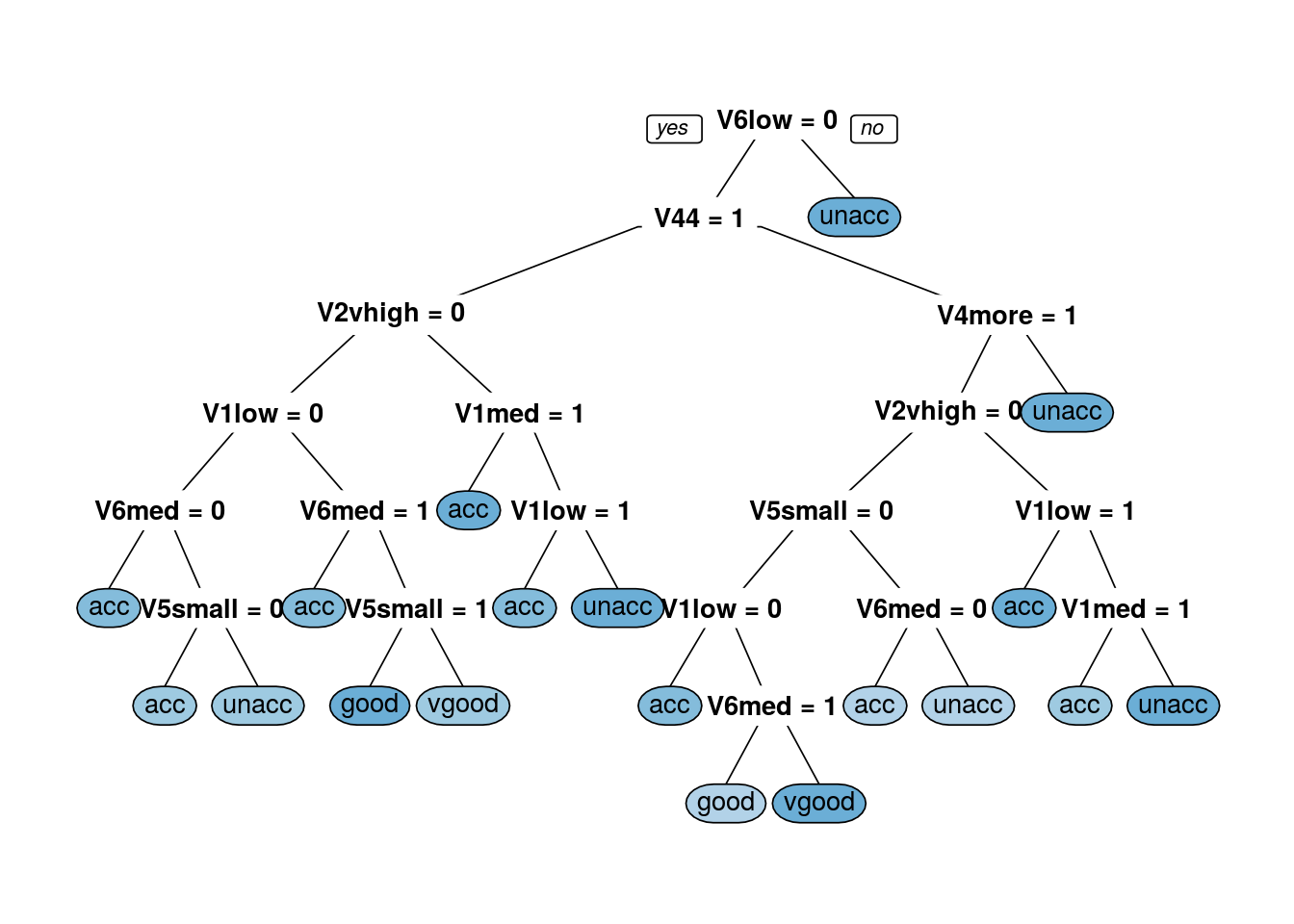
Prediction
Our model is trained with cp = 0.01123596. Now, it’s time to predict target variable for the whole test set.
test_pred_gini <- predict(dtree_fit_gini, newdata = testing)
confusionMatrix(test_pred_gini, testing$V7 ) #check accuracy## Confusion Matrix and Statistics
##
## Reference
## Prediction acc good unacc vgood
## acc 109 16 34 6
## good 5 7 0 0
## unacc 7 0 320 0
## vgood 3 1 0 8
##
## Overall Statistics
##
## Accuracy : 0.8605
## 95% CI : (0.8275, 0.8892)
## No Information Rate : 0.686
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 0.7133
## Mcnemar's Test P-Value : NA
##
## Statistics by Class:
##
## Class: acc Class: good Class: unacc Class: vgood
## Sensitivity 0.8790 0.29167 0.9040 0.57143
## Specificity 0.8571 0.98984 0.9568 0.99203
## Pos Pred Value 0.6606 0.58333 0.9786 0.66667
## Neg Pred Value 0.9573 0.96627 0.8201 0.98810
## Prevalence 0.2403 0.04651 0.6860 0.02713
## Detection Rate 0.2112 0.01357 0.6202 0.01550
## Detection Prevalence 0.3198 0.02326 0.6337 0.02326
## Balanced Accuracy 0.8681 0.64075 0.9304 0.78173The above results show that the classifier with the criterion as gini index is giving 86.05% of accuracy for the test set. In this case, our classifier with criterion gini index is giving better results.
Acknowledgement: the above data comes from a machine learning database and the codes are discussed at: http://dataaspirant.com/2017/02/03/decision-tree-classifier-implementation-in-r/
Methods used in Decision Trees for trade-off balance
Ensemble methods involve group of predictive models to achieve a better accuracy and model stability. Ensemble methods are known to impart supreme boost to tree based models.
Bagging is a technique used to reduce the variance of predictions by combining the result of multiple classifiers modeled on different sub-samples of the same data set.
Boosting refers to a family of algorithms which converts weak learner to strong learner by combing the prediction of each weak learner using methods like average/ weighted average or by considering a prediction that has a higher vote. Gradient boosting and XGboost are examples of boosting algorithms.
7.2 Random Forest
What is a Random Forest?
It is a kind of ensemble learning method that combines a set of weak models to form a powerful model. In the process it reduces dimensionality, removes outliers, treats missing values, and more importantly it is both a regression and classification machine learning approach.
How does it work?
In Random Forest, multiple trees are grown as opposed to a single tree in a decision tree model. Assume number of cases in the training set is N. Then, sample of these N cases is taken at random but with replacement. This sample will be the training set for growing the tree. Each tree is grown to the largest extent possible and without pruning.
To classify a new object based on attributes, each tree gives a classification i.e. “votes” for that class. The forest chooses the classification having the most votes (over all the trees in the forest) and in case of regression, it takes the average of outputs by different trees.
Key differences between decision trees and random forest
Decision trees proceed by searching for a split on every variable in every node random forest searches for a split only on one variable in a node - the variable that has the largest association with the target among all other explanatory variables but only on a subset of randomly selected explanatory variables that is tested for that node. At every node a new list is selected.
Therefore, eligible variable set will be different from node to node but the important ones will eventually be “voted in” based on their success in predicting the targert variable.
This random selection of explanatory variables at each node and which are different at each treee is known as bagging. For each tree the ratio between bagging and out of bagging is 60/40.
The important thing to note is that the trees are themselves not intpreted but they are used to collectively rank the importance of each variable.
Example Random Forest code for binary classification
In this example, a bank wanted to cross-sell term deposit product to its customers and hence it wanted to build a predictive model, which will identify customers who are more likely to respond to term deport cross-sell campaign.
Install and load randomForest library
# Load library
library(randomForest)## randomForest 4.6-14## Type rfNews() to see new features/changes/bug fixes.##
## Attaching package: 'randomForest'## The following object is masked from 'package:ggplot2':
##
## margin## Read data
Example<-read.csv(file="data/Decision_tree_and_RF/bank.csv",header = T)Input dataset has 20 independent variables and a target variable. The target variable y is binary.
names(Example)## [1] "age" "job" "marital" "education"
## [5] "default" "housing" "loan" "contact"
## [9] "month" "day_of_week" "duration" "campaign"
## [13] "pdays" "previous" "poutcome" "emp.var.rate"
## [17] "cons.price.idx" "cons.conf.idx" "euribor3m" "nr.employed"
## [21] "y"table(Example$y)/nrow(Example)##
## no yes
## 0.8905074 0.109492611% of the observations has target variable “yes” and remaining 89% observations take value “no”.
We will split the data sample into development and validation samples.
sample.ind <- sample(2,
nrow(Example),
replace = T,
prob = c(0.6,0.4))
Example.dev <- Example[sample.ind==1,]
Example.val <- Example[sample.ind==2,]
table(Example.dev$y)/nrow(Example.dev)##
## no yes
## 0.8881469 0.1118531Both development and validation samples have similar target variable distribution. This is just a sample validation.
class(Example.dev$y)## [1] "factor"Class of target or response variable is factor, so a classification Random Forest will be built. The current data frame has a list of independent variables, so we can make it formula and then pass as a parameter value for randomForest.
Make Formula
varNames <- names(Example.dev)
# Exclude ID or Response variable
varNames <- varNames[!varNames %in% c("y")]
# add + sign between exploratory variables
varNames1 <- paste(varNames, collapse = "+")
# Add response variable and convert to a formula object
rf.form <- as.formula(paste("y", varNames1, sep = " ~ "))Building Random Forest model
We will build 500 decision trees using Random Forest.
Example.rf <- randomForest(rf.form,
Example.dev,
ntree=500,
importance=T)
plot(Example.rf)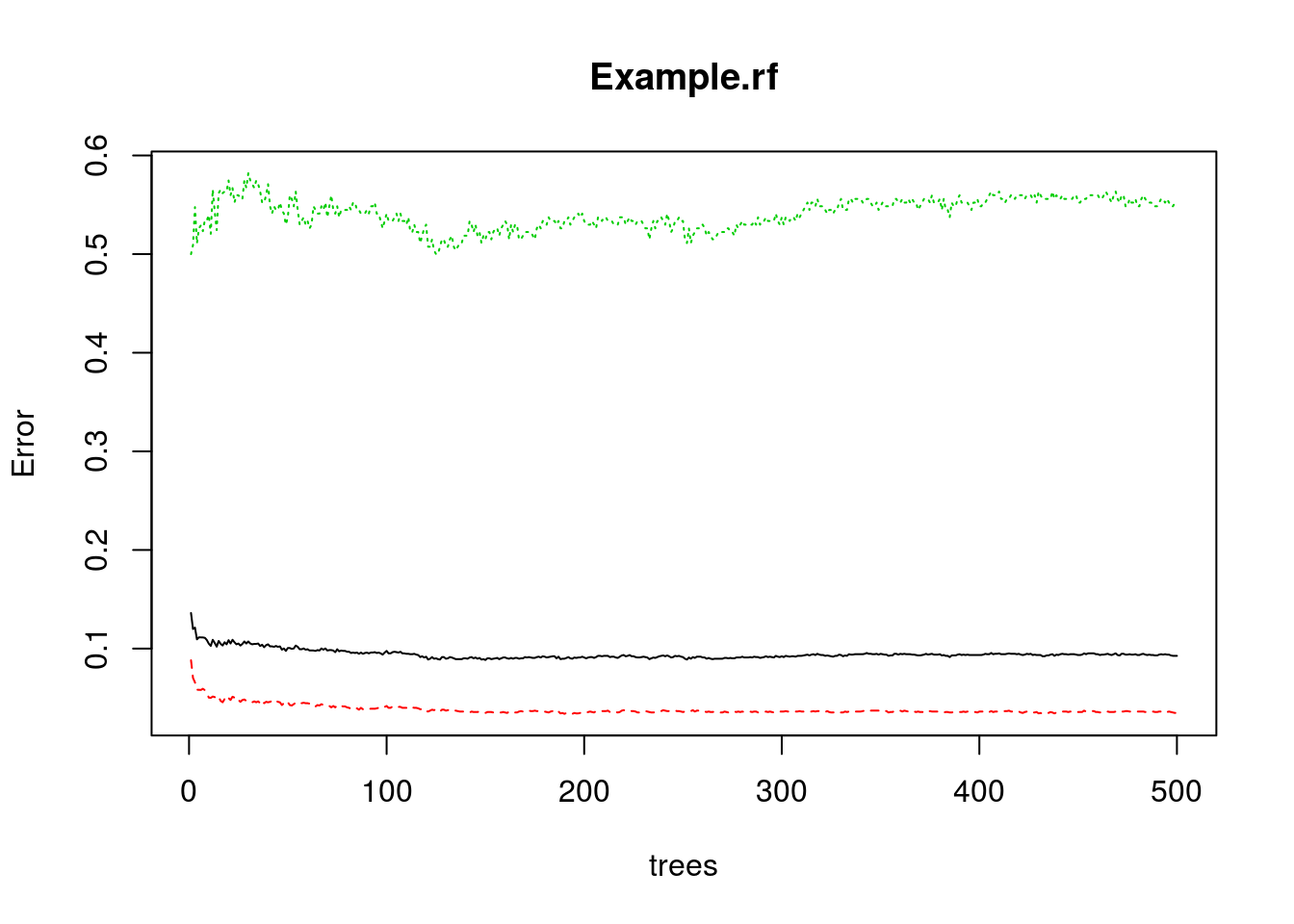
500 decision trees or a forest has been built using the Random Forest algorithm based learning. We can plot the error rate across decision trees. The plot seems to indicate that after 100 decision trees, there is not a significant reduction in error rate.
# Variable Importance Plot
varImpPlot(Example.rf,
sort = T,
main="Variable Importance",
n.var=5)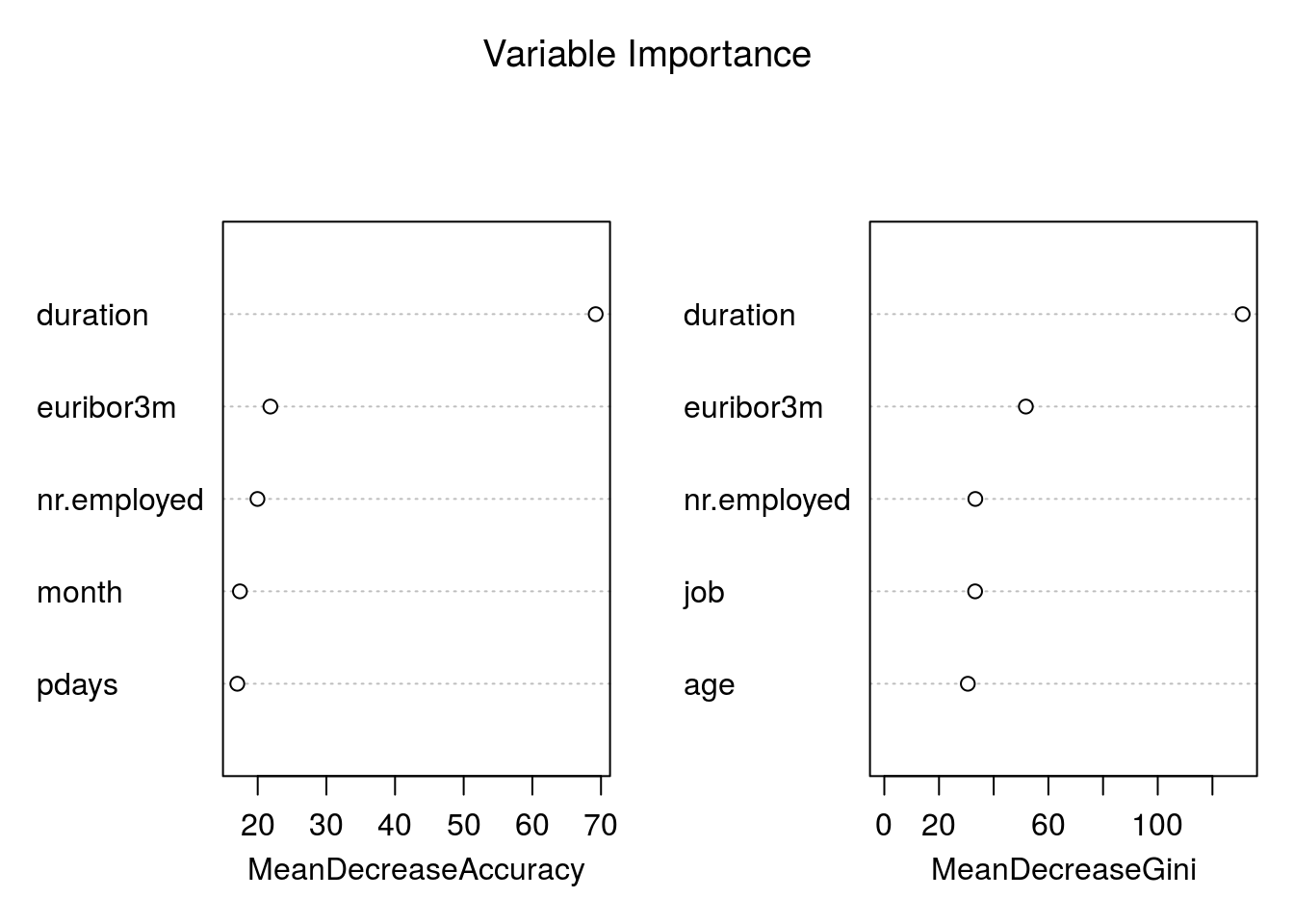
Variable importance plot is also a useful tool and can be plotted using varImpPlot function. Top 5 variables are selected and plotted based on Model Accuracy and Gini value. We can also get a table with decreasing order of importance based on a measure (1 for model accuracy and 2 node impurity)
# Variable Importance Table
var.imp <- data.frame(importance(Example.rf,
type=2))
# make row names as columns
var.imp$Variables <- row.names(var.imp)
var.imp[order(var.imp$MeanDecreaseGini,decreasing = T),]## MeanDecreaseGini Variables
## duration 131.064241 duration
## euribor3m 51.767706 euribor3m
## nr.employed 33.282654 nr.employed
## job 33.202606 job
## age 30.542239 age
## education 21.817563 education
## month 21.481160 month
## day_of_week 21.449264 day_of_week
## pdays 19.153022 pdays
## cons.conf.idx 15.695240 cons.conf.idx
## campaign 15.283873 campaign
## poutcome 13.860486 poutcome
## cons.price.idx 13.175296 cons.price.idx
## emp.var.rate 10.957252 emp.var.rate
## marital 8.270943 marital
## previous 7.556246 previous
## housing 7.012238 housing
## loan 5.045711 loan
## contact 4.187090 contact
## default 3.104346 defaultBased on Random Forest variable importance, the variables could be selected for any other predictive modelling techniques or machine learning.
Predict Response Variable Value using Random Forest
Generic predict function can be used for predicting response variable using Random Forest object.
# Predicting response variable
Example.dev$predicted.response <- predict(Example.rf ,Example.dev)confusionMatrix function from caret package can be used for creating confusion matrix based on actual response variable and predicted value.
# Load Library or packages
library(e1071)
library(caret)
## Loading required package: lattice
## Loading required package: ggplot2
# Create Confusion Matrix
confusionMatrix(data=Example.dev$predicted.response,
reference=Example.dev$y,
positive='yes')## Confusion Matrix and Statistics
##
## Reference
## Prediction no yes
## no 2128 0
## yes 0 268
##
## Accuracy : 1
## 95% CI : (0.9985, 1)
## No Information Rate : 0.8881
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 1
## Mcnemar's Test P-Value : NA
##
## Sensitivity : 1.0000
## Specificity : 1.0000
## Pos Pred Value : 1.0000
## Neg Pred Value : 1.0000
## Prevalence : 0.1119
## Detection Rate : 0.1119
## Detection Prevalence : 0.1119
## Balanced Accuracy : 1.0000
##
## 'Positive' Class : yes
## It has accuracy of 99.81%. Now we can predict response for the validation sample and calculate model accuracy for the sample.
# Predicting response variable
Example.val$predicted.response <- predict(Example.rf ,Example.val)
# Create Confusion Matrix
confusionMatrix(data=Example.val$predicted.response,
reference=Example.val$y,
positive='yes')## Confusion Matrix and Statistics
##
## Reference
## Prediction no yes
## no 1476 98
## yes 64 85
##
## Accuracy : 0.906
## 95% CI : (0.8912, 0.9193)
## No Information Rate : 0.8938
## P-Value [Acc > NIR] : 0.052603
##
## Kappa : 0.4606
## Mcnemar's Test P-Value : 0.009522
##
## Sensitivity : 0.46448
## Specificity : 0.95844
## Pos Pred Value : 0.57047
## Neg Pred Value : 0.93774
## Prevalence : 0.10621
## Detection Rate : 0.04933
## Detection Prevalence : 0.08648
## Balanced Accuracy : 0.71146
##
## 'Positive' Class : yes
## Accuracy level has dropped to 91.8% but still significantly higher.
Acknowledgement: the above data is from a machine-learning database and the code is discusses: http://dni-institute.in/blogs/random-forest-using-r-step-by-step-tutorial/*
7.3 Exercises
Titanic Data One of the reasons that the shipwreck led to such loss of life was that there were not enough lifeboats for the passengers and crew. Although there was some element of luck involved in surviving the sinking, some groups of people were more likely to survive than others, such as women, children, and the upper-class.
In this excerise, try to complete the analysis of what sorts of people were likely to survive. The data can be downloaded from https://goo.gl/At238b. Hint: Use decision tree.
Solutions to exercises can be found in appendix F.